pymodelfit.core.FunctionModel¶
- class pymodelfit.core.FunctionModel[source]¶
Bases: pymodelfit.core.ParametricModel
A base class for models that use a single function to map a numpy array input to an output (the function must be specified as the “f” method)
The following attributes must be defined:
- f()
A method that takes an array as the first argument and returns another array.
- _pars
A sequence of strings that define the names of attributes that are to be treated as the parameters for the model. If these are not defined, they will be initialized to the defaultparval value
- _filterfunc()
A function that performs any processing of inputs and outputs. Should call f() and have the same type of return value.
If type-checking is to be performed on the input, it should be performed in __call__() (see docstring for __call__() for syntax), but any mandatory input conversion should be done in _filterfunc().
- __init__()¶
x.__init__(...) initializes x; see help(type(x)) for signature
- __call__(x)[source]¶
Call the model function on the input x with the current parameters and return the result.
Raises ModelTypeError: If the input or output are incorrect type or dimensionality for this model. Note
If a subclass overrides this method to do type-checking, it should either call this method or call _filterfunc() with an array input and raise a ModelTypeError if there is a type problem
Methods
chi2Data([x, y, weights, ddof]) Computes the chi-squared statistic for the data assuming this model. f(x, *params) This abstract method must be overriden in subclasses. fitData([x, y, fixedpars, weights, ...]) Fit the provided data using algorithms from scipy.optimize, and adjust the model parameters to match. getCov() Computes the covariance matrix for the last fitData() call. getMCMC(x, y[, priors, datamodel]) Generate an Markov Chain Monte Carlo sampler for the data and model. inv(output, *args, **kwargs) Compute the inverse of this model for the requested output. isVarnumModel() Determines if the model represented by this class accepts a variable number of parameters (i.e. resampleFit([x, y, xerr, yerr, bootstrap, ...]) Estimates errors via resampling. residuals([x, y, retdata]) Compute residuals of the provided data against the model. stdData([x, y]) Determines the standard deviation of the model from data. Attributes
data The fitting data for this model. errors Error on the data. fittypes A Sequence of the available valid values for the fittype params A tuple of the parameter names. pardict A dictionary mapping parameter names to the associated values. parvals The values of the parameters in the same order as params weightstype Determines the statistical interpretation of the weights in data. - chi2Data(x=None, y=None, weights=None, ddof=1)[source]¶
Computes the chi-squared statistic for the data assuming this model.
Parameters: - x (array-like or None) – Input data value or None to use stored data
- y (array-like or None) – Output data value or None to use stored data
- weights (array-like or None) – Weights to adjust chi-squared, typically for error bars. Statistically interpreted based on the weightstype attribute. If None, any stored data will be used.
- ddof (int) – Delta Degrees of Freedom. The divisor used for the reduced chi-squared is n-m-ddof, where N is the number of points and m is the number of parameters in the model.
Returns: tuple of floats (chi2,reducedchi2,p-value)
- data None¶
The fitting data for this model. Should be either None, or a tuple(datain,dataout,weights). Note that the weights are interpreted statistically as errors based on the weightstype attribute.
- defaultparval = 1¶
The base default value if a parameter cannot get a default any other way.
- errors None¶
Error on the data. Sets the weights on data assuming the interpretation for errors given by weightstype. If data is None/missing, a TypeError will be raised.
- f(x, *params)[source]¶
This abstract method must be overriden in subclasses. It is interpreted as the function that takes an array (or array-like) as the first argument and returns an array of output values appropriate for the model.
model parameters are passed in as the rest of the arguments, in the order they are given in the _pars sequence.
- fitData(x=None, y=None, fixedpars='auto', weights=None, savedata=True, updatepars=True, fitf=False, contraction='sumsq', **kwargs)[source]¶
Fit the provided data using algorithms from scipy.optimize, and adjust the model parameters to match.
The fitting technique is sepcified by the fittype attribute of the object, which by default can be any of the optimization types in the scipy.optimize module (except for scalar minimizers)
The full fitting output is available in lastfit attribute after this method completes.
Parameters: - x (array-like) – The input values at which to evaluate the model. Valid shapes are those that this model will accept.
- y (array-like) – The expected output values for the model at the given x values. Valid shapes are those that this model will output.
- fixedpars (sequence of strings, ‘auto’ or None) – Parameter names to leave fixed. If ‘auto’ the fixed parameters are inferred from self.fixedpars (or all will be free parameters if self.fixedpars is absent). If None, all parameters will be free.
- weights –
Weights to use for fitting, statistically interpreted as inverse errors (not inverse variance). May be one of the following forms:
- None for equal weights
- an array of points that must match the output
- a 2-sequence of arrays (xierr,yierr) such that xierr matches the x-data and yierr matches the y-data
- a function called as f(params) that returns an array of weights that match one of the above two conditions
- savedata (bool) – If True, x,`y`,and weights will be saved to data. Otherwise, data will be discarded after fitting.
- updatepars (bool) – If True, sets the parameters on the object to the best-fit values.
- fitf (bool) – If True, the fit is performed directly against the f() method instead of against the model as evaluated if called (as altered using setCall()).
- contraction –
Only applies for optimize-based methods and is the technique used to convert vectors to figures of merit. this is composed of multiple string segments:
- these will be applied to each element of the vector first:
- ‘sq’: square
- ‘abs’:absolute value
- ‘’:raw value
- the contraction is performed after:
- ‘sum’: sum of all the elements
- ‘median’: median of all the elements
- ‘mean’: mean of all the elements
- ‘prod’: product of all the elements
- optionally,the string can include ‘frac’ to use the fractional version of the differnce vector instead of raw values. For the leastsq method, this is the only applicable value
- these will be applied to each element of the vector first:
kwargs are passed into the fitting function.
Returns: array of the best fit parameters Raises ModelTypeError: If the output of the model does not match the shape of y. See also
- fittype = 'leastsq'¶
The currently selected fitting technique.
- fittypes None[source]¶
A Sequence of the available valid values for the fittype attribute. (Read-only)
- fixedpars = ()¶
A sequence of the parameter names that by default should be kept fixed.
- getCov()[source]¶
Computes the covariance matrix for the last fitData() call.
Returns: The covariance matrix with variables in the same order as params. Diagonal entries give the variance in each parameter. Warning
This is not guaranteed to work for custom fit-types, but will always work with the default (leastsq) fit.
- getMCMC(x, y, priors={}, datamodel=None)[source]¶
Generate an Markov Chain Monte Carlo sampler for the data and model. This function requires the PyMC package for the MCMC internals and sampling.
Parameters: - x (array-like) – Input data value
- y (array-like) – Output data value
- priors (dictionary) –
Maps parameter names to the priors to assume for that parameter. There must be an entry for every parameter in the model. The prior specification can be in any of the following forms:
- A pymc.Stochastric object
- A 2-tuple (lower,upper) for a uniform prior
- A scalar > 0 to use a gaussian prior of the provided width centered at the current value of the parameter
- 0 for a Poisson prior with k set by the current value of the parameter
- datamodel –
Specifies the model to assume for the fitting data points. May be any of the following:
- None
- A normal distribution with sigma given by the data’s standard deviation.
- A tuple (dist,dataname,kwargs)
- The first element is the pymc.distribution to be used as the distribution representing the data and the second is the name of the argument to be associated with the FunctionModel1D’s output, and the third is kwargs for the distribution (“observed” and “data” will be ignored, as will the data argument)
- A sequence
- A normal distribution is used with sigma for each data point specified by the sequence. The length must match the model.
- A scalar
- A normal distribution with the given standard deviation.
Raises ValueError: If a prior is not provided for any parameter.
Returns: A pymc.MCMC object ready to sample for this model.
- inv(output, *args, **kwargs)¶
Compute the inverse of this model for the requested output.
Parameters: output – The output value of the model at which to compute the inverse. Returns: The input value at which the model produces output Raises ModelTypeError: If the model is not invertable for the provided data set.
- classmethod isVarnumModel()[source]¶
Determines if the model represented by this class accepts a variable number of parameters (i.e. number of parameters is set when the object is created).
Returns: True if this model has a variable number of parameters.
- pardict None¶
A dictionary mapping parameter names to the associated values.
- rangehint = None¶
A hint for the relevant range for this model. Should take the form (dim0lower,dim0upper,dim1lower,dim1upper,...) or None for no hint.
- resampleFit(x=None, y=None, xerr=None, yerr=None, bootstrap=False, modely=False, n=250, prefit=True, medianpars=False, plothist=False, **kwargs)[source]¶
Estimates errors via resampling. Uses the fitData function to fit the function many times while either using the “bootstrap” technique (resampling w/replacement), monte carlo estimates for the error, or both to estimate the error in the fit.
Parameters: - x (array-like or None) – The input data - if None, will be taken from the data attribute.
- y (array-like or None) – The output data - if None, will be taken from the data attribute.
- xerr (array-like, callable, or None) – Errors for the input data (assumed to be normally distributed), or if None, will be taken from the data. Alternatively, it can be a function that accepts the input data as the first argument and returns corresponding monte carlo sampled values.
- yerr (array-like, callable, or None) – Errors for the output data (assumed to be normally distributed), or if None, will be taken from the data. Alternatively, it can be a function that accepts the output data as the first argument and returns corresponding monte carlo sampled values.
- bootstrap (bool) – If True, the data is also resampled (with replacement).
- modely – If True, the fitting data will be generated by offseting from model values (evaluated at the x-values) instead of y-values.
- n (int) – The number of times to draw samples.
- prefit (bool) – If True, the data will be fit without resampling once before the samples are recorded.
- medianpars (bool) – If True, the median from the histogram will be set as the value for the parameter.
- plothist (bool or string) – If True, histograms will be plotted using matplotlib.pyplot.hist() for each of the parameters, or if it is a string, only the histogram for the requested parameter will be shown.
kwargs are passed into fitData
Returns: (histd,cov) where histd is a dictionary mapping parameters to their histograms and cov is the covariance matrix of the parameters in parameter order. Note
If x, y, xerr, or yerr are provided, they do not overwrite the stored data, unlike most other methods for this class.
- residuals(x=None, y=None, retdata=False)[source]¶
Compute residuals of the provided data against the model. E.g.
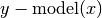 .
.Parameters: Returns: Residuals of model from y or if retdata is True, a tuple (x,y,residuals).
Return type: array-like
- stdData(x=None, y=None)[source]¶
Determines the standard deviation of the model from data. Data can either be provided or (by default) will be taken from the stored data.
Parameters: Returns: standard deviation of model from y
- weightstype None¶
Determines the statistical interpretation of the weights in data. Can be:
- ‘ierror’
Weights act as inverse errors (default)
- ‘ivar’
Weights act as inverse variance
- ‘error’
Weights act as errors (non-standard - this makes points with larger error bars count more towards the fit).
- ‘var’
Weights act as variance (non-standard - this makes points with larger error bars count more towards the fit).