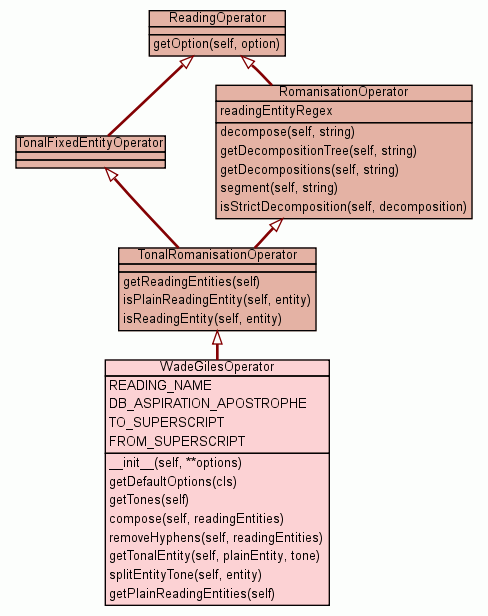
|
|
|
|
list
|
|
|
str
|
compose(self,
readingEntities)
Composes the given list of basic entities to a string by applying a
hyphen between syllables. |
source code
|
|
|
list of str
|
|
|
str
|
|
|
tuple
|
splitEntityTone(self,
entity)
Splits the entity into an entity without tone mark (plain entity) and
the entity's tone. |
source code
|
|
|
set of str
|
|
|
Inherited from TonalRomanisationOperator:
getReadingEntities,
isPlainReadingEntity,
isReadingEntity
Inherited from RomanisationOperator:
decompose,
getDecompositionTree,
getDecompositions,
isStrictDecomposition,
segment
Inherited from ReadingOperator:
getOption
Inherited from object:
__delattr__,
__getattribute__,
__hash__,
__new__,
__reduce__,
__reduce_ex__,
__repr__,
__setattr__,
__str__
|
|
|
READING_NAME = 'WadeGiles'
Unique name of reading
|
|
|
DB_ASPIRATION_APOSTROPHE = u'‘'
Default apostrophe used by Wade-Giles syllable data in database.
|
|
|
TO_SUPERSCRIPT = {1: u'¹', 2: u'²', 3: u'³', 4: u'⁴', 5: u'⁵'}
Mapping of tone numbers to superscript numbers.
|
|
|
FROM_SUPERSCRIPT = {u'²': 2, u'³': 3, u'¹': 1, u'⁴': 4, u'⁵': 5}
Mapping of superscript numbers to tone numbers.
|
|
Inherited from RomanisationOperator:
readingEntityRegex
|