Class RomanisationOperator
source code
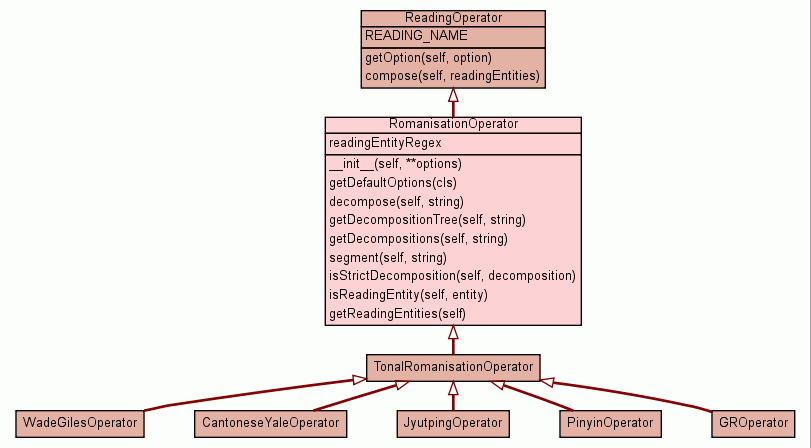
Defines an abstract ReadingOperator on text written in a
romanisation, i.e. text written in the Latin alphabet or written
in the Cyrillic alphabet.
Additional to decompose() provided by the class ReadingOperator this class offers a method getDecompositions() that returns several possible
decompositions in an ambiguous case.
This class itself can't be used directly, it has to be subclassed and
extended.
Decomposition
Transcriptions into the Latin alphabet generate the problem that
syllable boundaries or boundaries of entities belonging to single
Chinese characters aren't clear anymore once entities are grouped
together.
Therefore it is important to have methods at hand to separate this
strings and to split them into single entities. This though cannot
always be done in a clear and unambiguous way as several different
decompositions might be possible thus leading to the general case of ambiguous
decompositions.
Many romanisations do provide a way to tackle this problem. Pinyin
for example requires the use of an apostrophe (') when the
reverse process of splitting the string into syllables gets ambiguous.
The Wade-Giles romanisation in its strict implementation asks for a
hyphen used between all syllables. The LSHK's Jyutping when written
with tone marks will always be clearly decomposable.
The method isStrictDecomposition() can be implemented to check if
one possible decomposition is the strict
decomposition offered by the romanisation's protocol. This method
should guarantee that under all circumstances only one decomposed
version will be regarded as strict.
If no strict version is yielded and different decompositions exist
an unambiguous decomposition can not be made. These
decompositions can be accessed through method getDecompositions(), even in a cases where a strict
decomposition exists.
To Do (Impl):
Optimise decompose() as to incorporate segment() and prune the tree
while it is created. Does this though yield significant improvement?
Would at least be O(n).
|
|
|
|
list of str
|
decompose(self,
string)
Decomposes the given string into basic entities on a one-to-one
mapping level to Chinese characters. |
source code
|
|
|
list
|
getDecompositionTree(self,
string)
Decomposes the given string into basic entities that can be mapped to
one Chinese character each for all possible decompositions and
returns the possible decompositions as a lattice. |
source code
|
|
|
list of list of str
|
getDecompositions(self,
string)
Decomposes the given string into basic entities that can be mapped to
one Chinese character each for all possible decompositions. |
source code
|
|
|
list of list of str
|
segment(self,
string)
Takes a string written in the romanisation and returns the possible
segmentations as a list of syllables. |
source code
|
|
|
list of tuple
|
|
|
bool
|
|
|
bool
|
isStrictDecomposition(self,
decomposition)
Checks if the given decomposition follows the romanisation format
strictly to allow unambiguous decomposition. |
source code
|
|
|
bool
|
|
|
bool
|
|
|
set of str
|
|
|
Inherited from ReadingOperator:
compose,
getOption
Inherited from object:
__delattr__,
__getattribute__,
__hash__,
__new__,
__reduce__,
__reduce_ex__,
__repr__,
__setattr__,
__str__
|
|
list of list
|
|
|
list of list
|
_treeToList(tupleTree)
Converts a tree to a list containing all full paths from root to leaf
node. |
source code
|
|
|
|
readingEntityRegex = re.compile(r'([A-Za-z]+)')
Regular Expression for finding romanisation entities in input.
|
|
Inherited from ReadingOperator:
READING_NAME
|
|
Inherited from object:
__class__
|
|
Creates an instance of the RomanisationOperator.
- Parameters:
options - extra optionsdbConnectInst - instance of a DatabaseConnector, if none is given, default
settings will be assumed.strictSegmentation - if True segmentation (using segment()) and thus decomposition (using decompose()) will raise an exception if an
alphabetic string is parsed which can not be segmented into
single reading entities. If False the aforesaid
string will be returned unsegmented.case - if set to 'lower'/'upper', only
lower/upper case will be supported, respectively, if set to
'both' both upper and lower case will be supported. - Overrides:
object.__init__
|
|
Returns the reading operator's default options.
The default implementation returns an empty dictionary. The keyword
'dbConnectInst' is not regarded a configuration option of the operator
and is thus not included in the dict returned.
- Returns: dict
- the reading operator's default options.
- Overrides:
ReadingOperator.getDefaultOptions
- (inherited documentation)
|
|
Decomposes the given string into basic entities on a one-to-one
mapping level to Chinese characters. Decomposing can be ambiguous and
there are two assumptions made to solve this problem: If two subsequent
entities together make up a longer valid entity, then the decomposition
with the shorter entities can be disregarded. Furthermore it is assumed
that the reading provides rules to mark entity borders and that these
rules can be checked, so that the decomposition that abides by this rules
will be prefered. This check is done by calling isStrictDecomposition().
The given input string can contain other characters not supported by
the reading, e.g. punctuation marks. The returned list then contains a
mix of basic reading entities and other characters e.g. spaces and
punctuation marks.
- Parameters:
string (str) - reading string - Returns: list of str
- a list of basic entities of the input string
- Raises:
- Overrides:
ReadingOperator.decompose
|
|
Decomposes the given string into basic entities that can be mapped to
one Chinese character each for all possible decompositions and returns
the possible decompositions as a lattice.
- Parameters:
string (str) - reading string - Returns: list
- a list of all possible decompositions consisting of basic
entities as a lattice construct.
- Raises:
|
|
Decomposes the given string into basic entities that can be mapped to
one Chinese character each for all possible decompositions. This method
is a more general version of decompose().
The returned list construction consists of two entity types: entities
of the romanisation and other strings.
- Parameters:
string (str) - reading string - Returns: list of list of str
- a list of all possible decompositions consisting of basic
entities.
- Raises:
|
|
Takes a string written in the romanisation and returns the possible
segmentations as a list of syllables.
In contrast to decompose() this method merely segments continuous
entities of the romanisation. Characters not part of the romanisation
will not be dealt with, this is the task of the more general decompose
method.
- Parameters:
string (str) - reading string - Returns: list of list of str
- a list of possible segmentations (several if ambiguous) into
single syllables
- Raises:
|
|
Takes a string written in the romanisation and returns the possible
segmentations as a tree of syllables.
The tree is represented by tuples (syllable,
subtree).
- Parameters:
string (str) - reading string - Returns: list of tuple
- a tree of possible segmentations (if ambiguous) into single
syllables
|
_hasMergeableSyllables(self,
decomposition)
| source code
|
Checks if the given decomposition has two or more following syllables
which together make up a new syllable.
Segmentation can give several results with some possible syllables
being even further subdivided (e.g. tian to ti'an in
Pinyin). These segmentations are only secondary and the segmentation with
the longer syllables will be the one to take.
- Parameters:
decomposition (list of str) - decomposed reading string - Returns: bool
- True if following syllables make up a syllable
|
|
Checks if the given decomposition follows the romanisation format
strictly to allow unambiguous decomposition.
The romanisation should offer a way/protocol to make an unambiguous
decomposition into it's basic syllables possible as to make the process
of appending syllables to a string reversible. The testing on compliance
with this protocol has to be implemented here. Thus this method can only
return true for one and only one possible decomposition for all
strings.
- Parameters:
decomposition (list of str) - decomposed reading string - Returns: bool
- False, as this methods needs to be implemented by the sub class
|
|
Checks if the given string is a syllable supported by this
romanisation or a substring of one.
- Parameters:
string (str) - romanisation syllable or substring - Returns: bool
- true if this string is a substring of a syllable, false otherwise
|
|
Returns true if the given entity is recognised by the romanisation
operator, i.e. it is a valid entity of the reading returned by the
segmentation method.
Reading entities will be handled as being case insensitive.
- Parameters:
entity (str) - entity to check - Returns: bool
True if string is an entity of the reading,
False otherwise.- Overrides:
ReadingOperator.isReadingEntity
|
|
Gets a set of all entities supported by the reading.
The list is used in the segmentation process to find entity
boundaries. The default implementation will raise a
NotImplementedError.
- Returns: set of str
- set of supported syllables
|
|
Calculates the cross product (aka Cartesian product) of sets given as
lists.
Example:
>>> RomanisationOperator._crossProduct([['A', 'B'], [1, 2, 3]])
[['A', 1], ['A', 2], ['A', 3], ['B', 1], ['B', 2], ['B', 3]]
- Parameters:
singleLists (list of list) - a list of list entries containing various elements - Returns: list of list
- the cross product of the given sets
|
|
Converts a tree to a list containing all full paths from root to leaf
node.
The tree is given by tuples (leaf node element,
subtree).
Example:
>>> RomanisationOperator._treeToList(
... ('A', [('B', None), ('C', [('D', None), ('E', None)])]))
[['A', 'B'], ['A', 'C', 'D'], ['A', 'C', 'E']]
- Parameters:
tupleTree (tuple) - a tree realised through a tuple of a node and a subtree - Returns: list of list
- a list of all paths contained by the given tree
|