streams — Data Analysis and Processing Streams¶
The data processing stream is a network of data processing nodes connected by data pipes. There are several data processing node types:
- source nodes - provide data from data sources such as CSV files or database tables
- target nodes - nodes for consuming data and storing them or creating data visualizations
- record nodes - perform operations on whole records, such as merging, joining, aggregations
- field nodes - perform operations on particular fields, such as text substitution, field renaming, deriving new fields, restructuring
Data Processing Streams¶
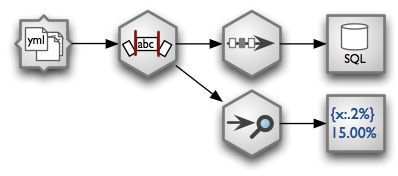
Example of a processing stream:
- load YAML fields from a directory - each file represents one record
- Strip all string fields.
- Remove duplicates and store unique records in a SQL database table
- Perform a data audit and pretty-print output using a formatted text printer
Constructing a stream the “object way”:
from brewery.nodes import *
from brewery.streams import *
import brewery.metadata as metadata
# Prepare nodes
nodes = {
"source": YamlDirectorySourceNode(path = "data/donations"),
"strip": StringStripNode(),
"distinct": DistinctNode(keys = ["year", "receiver", "project"]),
"target": SQLTableTarget(url = "postgres://localhost/data", table = "donations"),
"audit": AuditNode(),
"print": FormattedPrinterNode(output = "audit.txt")
}
# Configure nodes
nodes["source"].fields = metadata.FieldList([
("year", "integer"),
("receiver", "string"),
("project", "string"),
("requested_amount", "float"),
("received_amount", "float"),
("source_comment", "string")])
nodes["print"].header = u"field nulls empty\n" \
"-----------------------------------------------"
nodes["print"].format = u"{field_name:<30.30} {null_record_ratio:3.2%} {empty_string_count:>10}"
connections = [ ("source", "strip"),
("strip", "distinct"),
("distinct", "target"),
("strip", "audit"),
("audit", "print")
]
# Create and run stream
stream = Stream(nodes, connections)
stream.run()
The created audit.txt file will contain:
field nulls empty
-----------------------------------------------
year 0.00% 0
receiver 0.00% 5
project 0.51% 0
requested_amount 0.70% 0
received_amount 6.40% 0
source_comment 99.97% 0
The core class is Stream:
- class brewery.streams.Stream(nodes=None, connections=None)¶
Creates a data stream.
Parameters : - nodes - dictionary with keys as node names and values as nodes
- connections - list of two-item tuples. Each tuple contains source and target node or source and target node name.
- stream - another stream or
- configure(config=None)¶
Configure node properties based on configuration. Only named nodes can be configured at the moment.
config is a list of dictionaries with keys: node - node name, parameter - node parameter name, value - parameter value
- fork()¶
Creates a construction fork of the stream. Used for constructing streams in functional fashion. Example:
stream = Stream() fork = stream.fork() fork.csv_source("fork.csv") fork.formatted_printer() stream.run()
Fork responds to node names as functions. The function arguments are the same as node constructor (__init__ method) arguments. Each call will append new node to the fork and will connect the new node to the previous node in the fork.
To configure current node you can use fork.node, like:
fork.csv_source("fork.csv") fork.node.read_header = True
To set actual node name use set_name():
fork.csv_source("fork.csv") fork.set_name("source") ... source_node = stream.node("source")
To fork a fork, just call fork()
- run()¶
Run all nodes in the stream.
Each node is being wrapped and run in a separate thread.
When an exception occurs, the stream is stopped and all catched exceptions are stored in attribute exceptions.
- update(nodes=None, connections=None)¶
Adds nodes and connections specified in the dictionary. Dictionary might contain node names instead of real classes. You can use this method for creating stream from a dictionary that was created from a JSON file, for example.
The stream is constructed using nodes. For more information about nodes see Node Reference.
Running Streams¶
Streams are being run using Stream.run(). The stream nodes are executed in parallel - each node is run in separate thread.
Stream raises StreamError if there are issues with the network before or during initialization and finalization phases. When the stream is run and something happens, then StreamRuntimeError is raised which contains more detailed information:
- class brewery.streams.StreamRuntimeError(message=None, node=None, exception=None)¶
Exception raised when a node fails during run() phase.
- Attributes:
- message: exception message
- node: node where exception was raised
- exception: exception that was raised while running the node
- traceback: stack traceback
- inputs: array of field lists for each input
- output: output field list
- print_exception(output=None)¶
Prints exception and details in human readable form. You can specify IO stream object in output parameter. By default text is printed to standard output.
Preferred way of running the stream in manually written scripts is:
try:
stream.run()
except brewery.streams.StreamRuntimeError as e:
e.print_exception()
Forking Forks with Higher Order Messaging¶
There is another way of constructing streams which uses “higher order messaging”. It means, that instead of constructing the stream from nodes and connections, you pretend to “call” functions that process your data. In fact the function call is interpreted as step in processing stream construction.
trunk.csv_source("data.csv")
trunk.sample(1000)
trunk.aggregate(keys = ["year"])
trunk.formatted_printer(...)
Executing the functions as written might be very expensive in terms of time and memory. What is in fact happening is that instead of executing the data processing functions a stream network is being constructed and the construction is being done by using forked branches. To start, an empty stream and first fork has to be created:
from brewery.streams import *
stream = Stream()
main = stream.fork()
...
Now we have fork main. Each function call on main will append a new processing node to the fork and the new node will be connected to the previous node of the fork.
Function names are based on node names in most of the cases. There might be custom function names for some nodes in the future, but now there is just simple rule:
- de-camelize node name: CSVSourceNode to csv source node
- replace spaces with underscores: csv_source_node
- remove ‘node’ suffix: csv_source
Arguments to the function are the same as arguments for node constructor. If you want to do more node configuration you can access current node with node attribute of the fork:
main.node.keys = ["country"]
Run the stream as if it was constructed manually from nodes and connections:
stream.run()
There are plenty of situations where linear processing is not sufficient and we will need to have branches. To create another branch, we fork() a fork. For example, to attach a data audit to the stream insert following code right after the node we want to audit:
# we are in main at node after which we want to have multiple branches
audit = trunk.fork()
audit.audit()
audit.value_threshold(...)
audit.formatted_printer(...)
# continue main.* branch here...
Example¶
from brewery.streams import Stream
from brewery.metadata import FieldList
stream = Stream()
a_list = [
{"i": 1, "name": "apple"},
{"i": 2, "name": "bananna"},
{"i": 3, "name": "orange"}
]
fields = FieldList(["i", "name"])
trunk = stream.fork()
trunk.record_list_source(a_list = a_list, fields = fields)
trunk.derive("i*100 + len(name)")
csv_branch = trunk.fork()
trunk.record_list_target()
record_target = trunk.node
csv_branch.csv_target("test_stream.csv")
stream.run()
for record in record_target.records:
print record
Output will be:
{'i': 1, 'name': 'apple', 'new_field': 105}
{'i': 2, 'name': 'banana', 'new_field': 207}
{'i': 3, 'name': 'orange', 'new_field': 306}
The newly created test_stream.csv file will contain:
i,name,new_field
1,apple,105
2,banana,207
3,orange,306
Custom nodes¶
To implement custom node, one has to subclass the Node class:
- class brewery.streams.Node¶
Creates a new data processing node.
Attributes : - inputs: input pipes
- outputs: output pipes
- description: custom node annotation
- configure(config, protected=False)¶
Configure node.
Parameters : - config - a dictionary containing node attributes as keys and values as attribute values. Key type is ignored as it is used for node creation.
- protected - if set to True only non-protected attributes are set. Attempt to set protected attribute will result in an exception. Use protected when you are configuring nodes through a user interface or a custom tool. Default is False: all attributes can be set.
If key in the config dictionary does not refer to a node attribute specified in node description, then it is ignored.
- finalize()¶
Finalizes the node. Default implementation does nothing.
- classmethod identifier()¶
Returns an identifier name of the node class. Identifier is used for construction of streams from dictionaries or for any other out-of-program constructions.
Node identifier is specified in the node_info dictioanry as name. If no explicit identifier is specified, then decamelized class name will be used with node suffix removed. For example: CSVSourceNode will be csv_source.
- initialize()¶
Initializes the node. Initialization is separated from creation. Put any Node subclass initialization in this method. Default implementation does nothing.
- input¶
Return single node imput if exists. Convenience property for nodes which process only one input. Raises exception if there are no inputs or are more than one imput.
- input_fields¶
Return fields from input pipe, if there is one and only one input pipe.
- output_field_names¶
Convenience method for gettin names of fields generated by the node. For more information see brewery.nodes.Node.output_fields()
- output_fields¶
Return fields passed to the output by the node.
Subclasses should override this method. Default implementation returns same fields as input has, raises exception when there are more inputs or if there is no input connected.
- put(obj)¶
Put row into all output pipes.
Raises NodeFinished exception when node’s target nodes are not receiving data anymore. In most cases this exception might be ignored, as it is handled in the node thread wrapper. If you want to perform necessary clean-up in the run() method before exiting, you should handle this exception and then re-reaise it or just simply return from run().
This method can be called only from node’s run() method. Do not call it from initialize() or finalize().
- put_record(obj)¶
Put record into all output pipes. Convenience method. Not recommended to be used.
Depreciated.
- reset_type(name)¶
Remove all retype information for field name
- retype(name, **attributes)¶
Retype an output field name to field field.
- run()¶
Main method for running the node code. Subclasses should implement this method.
Node uses pipes for communication. SimplePipe is abstract class that should be used as base class for any Pipe implementation:
The Pipe class uses Python threading for node thread concurrency:
- class brewery.streams.Pipe(buffer_size=1000)¶
Creates uni-drectional data pipe for passing data between two threads in batches of size buffer_size.
If receiving node is finished with source data and does not want anything any more, it should send done_receiving() to the pipe. In most cases, stream runner will send done_receiving() to all input pipes when node’s run() method is finished.
If sending node is finished, it should send done_sending() to the pipe, however this is not necessary in most cases, as the method for running stream flushes outputs automatically on when node run() method is finished.
- closed()¶
Return True if pipe is closed - not sending or not receiving data any more.
- done_receiving()¶
Close pipe from either side
- done_sending()¶
Close pipe from sender side
- put(obj)¶
Put data object into the pipe buffer. When buffer is full it is enqueued and receiving node can get all buffered data objects.
Puttin object into pipe is not thread safe. Only one thread sohuld write to the pipe.
- rows()¶
Get data object from pipe. If there is no buffer ready, wait until source object sends some data.