ds — Data Stores¶
Warning
This module will be very likely renamed from ds to ‘stores’. Currently there is confusion whether ‘ds’ means ‘data stores’ or ‘data streams’. There is also another module called streams: processing streams based on nodes connected with pipes.
Overview¶
Data stores provide interface for common way of reading from and writing to various structured data stores through structured data streams. It allows you to read CSV file and merge it with Excel spreadsheet or Google spreadsheet, then perform cleansing and write it to a relational database table or create a report.
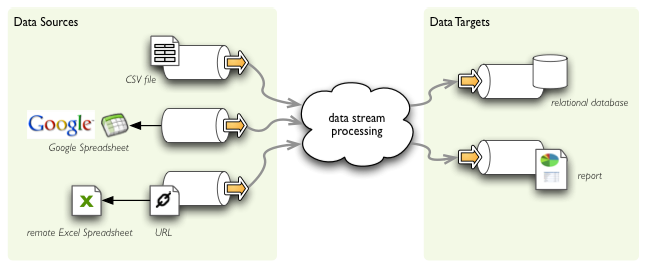
Example of streaming data between data stores.
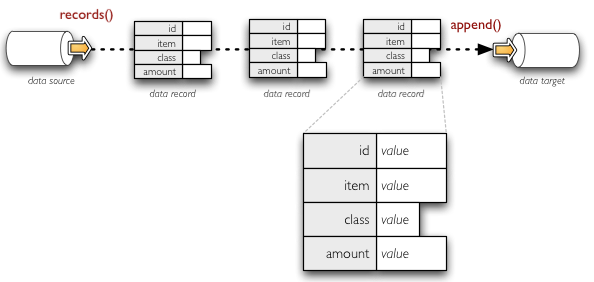
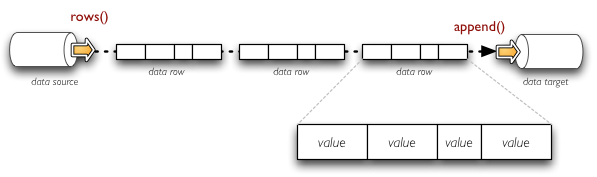
The data streams can be compared to file-like stream objects where structured data is being passed instead of bytes. There are two ways how to look at structured data: as a set of lists of values or as a set of key-value pairs (set of dictionaries). Some sources provide one or the other way of looking at the data, some processing is better with the list form, another might be better with the dictionary form. Brewery allows you to use the form which is most suitable for you.
Example of streaming data as sequence of rows - tuples of values.
Example of streaming data as sequence of records - dictionaries with key-value pairs.
At any time you are able to retrieve stream metadata: list of fields being streamed. For more information see metadata where you can find more information.
Data Sources¶
| Data source | Description | Dataset reference |
|---|---|---|
| csv | Comma separated values (CSV) file/URI resource | file path, file-like object, URL |
| xls | MS Excel spreadsheet | file path, URL |
| gdoc | Google Spreadsheet | spreadsheet key or name |
| sql | Relational database table | connection + table name |
| mongodb | MongoDB database collection | connection + table name |
| yamldir | Directory containing yaml files - one file per record | directory |
| elasticsearch | Elastic Search – Open Source, Distributed, RESTful, Search Engine |
Data sources should implement:
- initialize() - delayed initialisation: get fields if they are not set, open file stream, ...
- rows() - returns iterable with value tuples
- records() - returns iterable with dictionaries of key-value pairs
Should provide property fields, optionally might provide assignment of this property.
Data Targets¶
| Data target | Description |
|---|---|
| csv | Comma separated values (CSV) file/URI resource |
| sql | Relational database table |
| mongodb | MongoDB database collection |
| yamldir | Directory containing yaml files - one file per record |
| jsondir | Directory containing json files - one file per record (not yet) |
| html | HTML file or a string target |
| elasticsearch | Elastic Search – Open Source, Distributed, RESTful, Search Engine |
Data targets should implement:
- initialize() - create dataset if required, open file stream, open db connection, ...
- append(object) - appends object as row or record depending whether it is a dictionary or a list
Base Classes¶
Use these classes as super classes for your custom structured data sources or data targets.
- class brewery.ds.DataStream¶
A data stream object – abstract class.
The subclasses should provide:
- fields
fields are FieldList objects representing fields passed through the receiving stream - either read from data source (DataSource.rows()) or written to data target (DataTarget.append()).
Subclasses should populate the fields property (or implenet an accessor).
The subclasses might override:
- initialize()
- finalize()
The class supports context management, for example:
with ds.CSVDataSource("output.csv") as s: for row in s.rows(): print row
In this case, the initialize() and finalize() methods are called automatically.
- finalize()¶
Subclasses might put finalisation code here, for example:
- closing a file stream
- sending data over network
- writing a chart image to a file
Default implementation does nothing.
- initialize()¶
Delayed stream initialisation code. Subclasses might override this method to implement file or handle opening, connecting to a database, doing web authentication, ... By default this method does nothing.
The method does not take any arguments, it expects pre-configured object.
- class brewery.ds.DataSource¶
Abstrac class for data sources.
- read_fields(limit=0, collapse=False)¶
Read field descriptions from data source. You should use this for datasets that do not provide metadata directly, such as CSV files, document bases databases or directories with structured files. Does nothing in relational databases, as fields are represented by table columns and table metadata can obtained from database easily.
Note that this method can be quite costly, as by default all records within dataset are read and analysed.
After executing this method, stream fields is set to the newly read field list and may be configured (set more appropriate data types for example).
Arguments : - limit: read only specified number of records from dataset to guess field properties
- collapse: whether records are collapsed into flat structure or not
Returns: tuple with Field objects. Order of fields is datastore adapter specific.
- records()¶
Return iterable object with dict objects. This is one of two methods for reading from data source. Subclasses should implement this method.
- rows()¶
Return iterable object with tuples. This is one of two methods for reading from data source. Subclasses should implement this method.
- class brewery.ds.DataTarget¶
Abstrac class for data targets.
- append(object)¶
Append an object into dataset. Object can be a tuple, array or a dict object. If tuple or array is used, then value position should correspond to field position in the field list, if dict is used, the keys should be valid field names.
Sources¶
- class brewery.ds.CSVDataSource(resource, read_header=True, dialect=None, encoding=None, detect_header=False, sample_size=200, skip_rows=None, empty_as_null=True, fields=None, **reader_args)¶
Creates a CSV data source stream.
Attributes : - resource: file name, URL or a file handle with CVS data
- read_header: flag determining whether first line contains header or not. True by default.
- encoding: source character encoding, by default no conversion is performed.
- detect_headers: try to determine whether data source has headers in first row or not
- sample_size: maximum bytes to be read when detecting encoding and headers in file. By default it is set to 200 bytes to prevent loading huge CSV files at once.
- skip_rows: number of rows to be skipped. Default: None
- empty_as_null: treat empty strings as Null values
Note: avoid auto-detection when you are reading from remote URL stream.
- initialize()¶
Initialize CSV source stream:
- perform autodetection if required:
- detect encoding from a sample data (if requested)
#. detect whether CSV has headers from a sample data (if requested)
create CSV reader object
read CSV headers if requested and initialize stream fields
If fields are explicitly set prior to initialization, and header reading is requested, then the header row is just skipped and fields that were set before are used. Do not set fields if you want to read the header.
All fields are set to storage_type = string and analytical_type = unknown.
- class brewery.ds.GoogleSpreadsheetDataSource(spreadsheet_key=None, spreadsheet_name=None, worksheet_id=None, worksheet_name=None, query_string='', username=None, password=None)¶
Creates a Google Spreadsheet data source stream.
Attributes : - spreadsheet_key: The unique key for the spreadsheet, this
usually in the the form ‘pk23...We’ or ‘o23...423.12,,,3’.
spreadsheet_name: The title of the spreadsheets.
worksheet_id: ID of a worksheet
worksheet_name: name of a worksheet
query_string: optional query string for row selection
username: Google account user name
password: Google account password
You should provide either spreadsheet_key or spreadsheet_name, if more than one spreadsheet with given name are found, then the first in list returned by Google is used.
For worksheet selection you should provide either worksheet_id or worksheet_name. If more than one worksheet with given name are found, then the first in list returned by Google is used. If no worksheet_id nor worksheet_name are provided, then first worksheet in the workbook is used.
For details on query string syntax see the section on sq under http://code.google.com/apis/spreadsheets/reference.html#list_Parameters
- initialize()¶
Connect to the Google documents, authenticate.
- class brewery.ds.XLSDataSource(resource, sheet=None, encoding=None, skip_rows=None, read_header=True)¶
Creates a XLS spreadsheet data source stream.
Attributes : resource: file name, URL or file-like object
sheet: sheet index number (as int) or sheet name (as str)
- read_header: flag determining whether first line contains header or not.
True by default.
- initialize()¶
Initialize XLS source stream:
- class brewery.ds.SQLDataSource(connection=None, url=None, table=None, statement=None, schema=None, autoinit=True, **options)¶
Creates a relational database data source stream.
Attributes : - url: SQLAlchemy URL - either this or connection should be specified
- connection: SQLAlchemy database connection - either this or url should be specified
- table: table name
- statement: SQL statement to be used as a data source (not supported yet)
- autoinit: initialize on creation, no explicit initialize() is needed
- options: SQL alchemy connect() options
- initialize()¶
Initialize source stream. If the fields are not initialized, then they are read from the table.
- class brewery.ds.MongoDBDataSource(collection, database=None, host=None, port=None, expand=False, **mongo_args)¶
Creates a MongoDB data source stream.
Attributes : collection: mongo collection name
database: database name
host: mongo database server host, default is localhost
port: mongo port, default is 27017
- expand: expand dictionary values and treat children as top-level keys with dot ‘.’
separated key path to the child..
- initialize()¶
Initialize Mongo source stream:
- class brewery.ds.YamlDirectoryDataSource(path, extension='yml', expand=False, filename_field=None)¶
Creates a YAML directory data source stream.
The data source reads files from a directory and treats each file as single record. For example, following directory will contain 3 records:
data/ contract_0.yml contract_1.yml contract_2.ymlOptionally one can specify a field where file name will be stored.
Attributes : path: directory with YAML files
extension: file extension to look for, default is yml,if none is given, then all regular files in the directory are read
- expand: expand dictionary values and treat children as top-level keys with dot ‘.’
separated key path to the child.. Default: False
filename_field: if present, then filename is streamed in a field with given name, or if record is requested, then filename will be in first field.
Targets¶
- class brewery.ds.CSVDataTarget(resource, write_headers=True, truncate=True, encoding='utf-8', dialect=None, fields=None, **kwds)¶
Creates a CSV data target
Attributes : - resource: target object - might be a filename or file-like object
- write_headers: write field names as headers into output file
- truncate: remove data from file before writing, default: True
- class brewery.ds.SQLDataTarget(connection=None, url=None, table=None, schema=None, truncate=False, create=False, replace=False, add_id_key=False, id_key_name=None, buffer_size=None, fields=None, concrete_type_map=None, **options)¶
Creates a relational database data target stream.
Attributes : - url: SQLAlchemy URL - either this or connection should be specified
- connection: SQLAlchemy database connection - either this or url should be specified
- table: table name
- truncate: whether truncate table or not
- create: whether create table on initialize() or not
- replace: Set to True if creation should replace existing table or not, otherwise initialization will fail on attempt to create a table which already exists.
- options: other SQLAlchemy connect() options
- add_id_key: whether to add auto-increment key column or not. Works only if create is True
- id_key_name: name of the auto-increment key. Default is ‘id’
- buffer_size: size of INSERT buffer - how many records are collected before they are inserted using multi-insert statement. Default is 1000
- fields : fieldlist for a new table
Note: avoid auto-detection when you are reading from remote URL stream.
- finalize()¶
Closes the stream, flushes buffered data
- initialize()¶
Initialize source stream:
- class brewery.ds.MongoDBDataTarget(collection, database=None, host=None, port=None, truncate=False, expand=False, **mongo_args)¶
Creates a MongoDB data target stream.
Attributes : collection: mongo collection name
database: database name
host: mongo database server host, default is localhost
port: mongo port, default is 27017
- expand: expand dictionary values and treat children as top-level keys with dot ‘.’
separated key path to the child..
truncate: delete existing data in the collection. Default: False
- initialize()¶
Initialize Mongo source stream:
- class brewery.ds.YamlDirectoryDataTarget(path, filename_template='record_${__index}.yml', expand=False, filename_start_index=0, truncate=False)¶
Creates a directory data target with YAML files as records.
Attributes : - path: directory with YAML files
- extension: file extension to use
- expand: expand dictionary values and treat children as top-level keys with dot ‘.’ separated key path to the child.. Default: False
- filename_template: template string used for creating file names. ${key} is replaced with record value for key. __index is used for auto-generated file index from filename_start_index. Default filename template is record_${__index}.yml which results in filenames record_0.yml, record_1.yml, ...
- filename_start_index - first value of __index filename template value, by default 0
- filename_field: if present, then filename is taken from that field.
- truncate: remove all existing files in the directory. Default is False.
- class brewery.ds.StreamAuditor(distinct_threshold=10)¶
Target stream for auditing data values from stream. For more information about probed value properties, please refer to brewery.dq.FieldStatistics
- append(obj)¶
Probe row or record and update statistics.
- field_statistics¶
Return field statistics as dictionary: keys are field names, values are brewery.dq.FieldStatistics objects
- class brewery.ds.SimpleHTMLDataTarget(resource, html_header=True, html_footer=None, write_headers=True, table_attributes=None)¶
Creates a HTML data target with simple naive HTML generation. No package that generates document node tree is used, just plain string concatenation.
Attributes : - resource: target object - might be a filename or file-like object - you can stream HTML table data into existing opened file.
- write_headers: create table headers, default: True. Field labels will be used, if field has no label, then fieln name will be used.
- table_attributes: <table> node attributes such as class, id, ...
- html_header: string to be used as HTML header. If set to None only <table> will be generated. If set to True then default header is used. Default is True.
- html_header: string to be used as HTML footer. Works in similar way as to html_header.
Note: No HTML escaping is done. HTML tags in data might break the output.