metadata — Information about data structure¶
While working with structured data it is helpful to know how the structure looks like, what are the fields, what are their types.
Field types¶
There are two kinds of field types: storage type and analytical type. The storage type specifies how the value is being stored in the source, the type is normalized. Another type is analytical type which is used in data mining, defines if the field can be used by particular algorithm and how the field is treated by mining algorithms.
Storage types
| Storage Type | Description |
|---|---|
| string | names, labels, short descriptions; mostly implemeted as VARCHAR type in database, or can be found as CSV file fields |
| text | longer texts, long descriptions, articles |
| integer | discrete values |
| float | numerical value with floating point |
| boolean | binary value, mostly implemented as small integer |
| date | calendar date representation |
Analytical types
| Analytical Type | Description |
|---|---|
| set | Values represent categories, like colors or contract. types. Fields of this type might be numbers which represent for example group numbers, but have no mathematical interpretation. For example addition of group numbers 1+2 has no meaning. |
| ordered_set | Similar to set field type, but values can be ordered in a meaningful order. |
| discrete | Set of integers - values can be ordered and one can perform arithmetic operations on them, such as: 1 contract + 2 contracts = 3 contracts |
| flag | Special case of set type where values can be one of two types, such as 1 or 0, ‘yes’ or ‘no’, ‘true’ or ‘false’. |
| range | Numerical value, such as financial amount, temperature |
| default | Analytical type is not explicitly set and default type for fields storage type is used. Refer to the table of default types. |
| typeless | Field has no analytical relevance. |
- Default analytical types:
- integer is discrete
- float is range
- unknown, string, text, date are typeless
Fields and Field Lists¶
Main metadata class is Field which gives information about name, types and other useful data attributes. Field might represent a database column in a SQL database, a key in a dictionary-like record...
- class brewery.metadata.Field(name, storage_type='unknown', analytical_type='typeless', concrete_storage_type=None, missing_values=None, label=None)¶
Metadata - information about a field in a dataset or in a datastream.
Attributes : - name - field name
- label - optional human readable field label
- storage_type - Normalized data storage type. The data storage type is abstracted
- concrete_storage_type (optional, recommended) - Data store/database dependent storage type - this is the real name of data type as used in a database where the field comes from or where the field is going to be created (this might be null if unknown)
- analytical_type - data type used in data mining algorithms
- missing_values (optional) - Array of values that represent missing values in the dataset for given field
- to_dict()¶
Return dictionary representation of the field.
In most cases we are dealing with structured data here, therefore we are working with multiple fields and values at once. For that purpose there is FieldList – ordered list of field descriptions:
Fields can be compared using == and != operators. They are equal if all attributes are equal. Getting a string representation str(field) of a field returns field name.
name
- class brewery.metadata.FieldList(fields=None)¶
Create a list of Field objects from a list of strings, dictionaries or tuples
How fields are consutrcuted:
- string: field name is set
- tuple: (field_name, storaget_type, analytical_type), the field_name is obligatory, rest is optional
- dict: contains key-value pairs for initializing a Field object
For strings and in if not explicitly specified in a tuple or a dict case, then following rules apply:
- storage_type is set to unknown
- analytical_type is set to typeless
- append(field)¶
Appends a field to the list. This method requires field to be instance of Field
- copy(fields=None)¶
Return a shallow copy of the list.
Parameters : - fields - list of fields to be copied.
- field(name)¶
Return a field with name name
- fields(names=None)¶
Return a tuple with fields. names specifies which fields are returned. When names is None all fields are returned.
- index(field)¶
Return index of a field
- indexes(fields)¶
Return a tuple with indexes of fields from fields in a data row. Fields should be a list of Field objects or strings.
This method is useful when it is more desirable to process data as rows (arrays), not as dictionaries, for example for performance purposes.
- names(indexes=None)¶
Return names of fields in the list.
Parameters : - indexes - list of indexes for which field names should be collected. If set to None then all field names are collected - this is default behaviour.
- retype(dictionary)¶
Retype fields according to the dictionary. Dictionary contains field names as keys and field attribute dictionary as values.
- selectors(fields=None)¶
Return a list representing field selector - which fields are selected from a row.
In addition, the FieldList behaves as a list: implements len(), del, [] with field index, += for appending fields, + for creating new field list by concatenating two other lists.
Field lists are used in data sources, data targets, processing streams, nodes, ... They are mostly present in the form of a fields attribute (in a class) or function parameter with the same name. To make it easy to quickly construct list of fields with all necessary metadata you can do:
import brewery.metadata as metadata
fields = metadata.FieldList(["organisation", "address", "type", "amount"])
If you are implementing a function that changes data structure, do not change the fields you have received from the source. Make a copy and do modifications in the copy:
import brewery.streams
class AppendTimestampNode(streams.Node):
def initialize(self):
# Create a copy
fields = self.input.fields.copy()
# Append custom field(s)
timestamp_field = Field("timestamp", storage_type = "date")
fields.append(timestamp_field)
self.output_fields = fields
Concrete storage type¶
Each field can have specified concrete storage type - closest type definition to the real storage. Value of this attribute is dependent on a backend providing field information about data source or data target. For example, SQL backend can use type class or type class instance. Reason for storing concrete storage type is to preserve the type in homogenous environment in the first place. Second reason is to allow custom mappings between backend data types.
Brewery does not perform any mapping currently. If the backends are not compatible, the concrete storage is simply ignored and default type from normalized plain storage_type is used.
Field mapping¶
Quite common operation is field renaming and dropping of unused fields, for example those that were already transformed. This might be also called field filtering.
- class brewery.metadata.FieldMap(rename=None, drop=None, keep=None)¶
Creates a field map. rename is a dictionary where keys are input field names and values are output field names. drop is list of field names that will be dropped from the stream. If keep is used, then all fields are dropped except those specified in keep list.
- field_selectors(fields)¶
Returns selectors of fields to be used by itertools.compress(). This is the preferred way of field filtering.
- map(fields)¶
Map fields according to the FieldMap: rename or drop fields as specified. Returns a FieldList object.
- row_filter(fields)¶
Returns an object that will convert rows with structure specified in fields. You can use the object to filter fields from a row (list, array) according to this map.
For example our requirement is to do following field mapping/filtering:
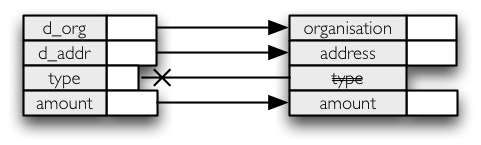
import brewery.metadata as metadata
fields = metadata.FieldList(["d_org", "d_addr", "type", "amount"])
map = metadata.FieldMap(rename = {"d_org": "organisation", "d_addr":"address"}, drop = ["type"])
mapped_fields = map.map(fields)
print(mapped_fields.names())
# Now we have mapped_fields = ['organisation', 'address', 'amount']
To apply field mapping onto a row (list, tuple), there is RowFieldFilter. Following example shows how to filter fields from list of rows:
# Assume that we have rows with structure specified in previous example in ``fields``
filter = map.row_filter(fields)
output = []
for row in rows:
output.append(filter.filter(row))
# Output will contain only fields as in ``mapped_fields`` from the previous example