‘filesysobjects’ - Addressing files and directories¶
The package ‘filesysobjects’ supports the hierarchical navigation on filesystems. This is similar to the hierarchy of object oriented class hierarchies
The basic idea is to start a search operation for filenames from a directory position on upward and get the first match. The first match is than the deepest position, which in terms of object orientation represents the most specialized class.
A typical application is the drop-in design of regression and unit tests. In those cases a frequent requirement is the provisioning of test dummies. This could be simply designed as an executable file for providing test values, or simulating the environment for a specific test. When performing multiple tests on the same resource, the upward-search operation provides for automatic detection from multiple cases which are positioned deeper within the filesystem hierarchy. Thus these cases simply inherit an already present resource, which in addition covers higher positioned files by a higher degree of specialization.
Filesystem Elements as Objects¶
The common filesystems inherently support basic features for the application of hierarchical name binding structures. This is commonly utilized by applications via various search path algorithms e.g. the PATH variable for executables. The package ‘filesystemobjects’ extends this feature for the upward search within hierarchies including the search and extension by subpaths as branches. This simulates inheritance within classes and objects.
The following two example features already provide for the required basic superposition of inheritance for files in directory hierarchies.
- The search for files and/or relative paths from a given directory on upwards.
- The extension of search paths with any sub-directory portion from a given directory on upwards.
This provides e.g. the superposition of equal named files within different levels of the directory tree. Thus a search operation upward from a start position will match the same name multiple times, similar to a method or member variable of a class within an inheritance hierarchy.
The following figure depicts the structure for some examples( see testdata.examples).
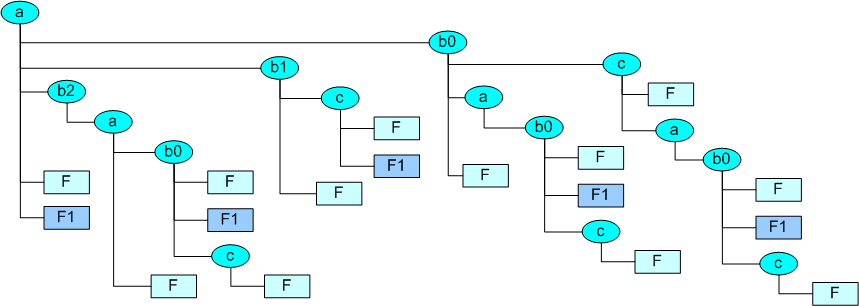
- Or as tree output:
a |-- b0 | |-- a | | `-- b0 | | |-- c | | | `-- F | | |-- F | | `-- F1 | |-- c | | |-- a | | | `-- b0 | | | |-- c | | | | `-- F | | | |-- F | | | `-- F1 | | `-- F | `-- F |-- b1 | |-- c | | |-- F | | `-- F1 | `-- F |-- b2 | `-- a | |-- b0 | | |-- c | | | `-- F | | |-- F | | `-- F1 | `-- F |-- F `-- F1
The basic idea is similar to any OO pattern for the implementation of holomorpy by upward search for identical named elements. Where by default the first match terminates the search. Thus the first match defines the concrete feature, whereas the possible following additional matches in the higher location of the filesystem tree were hidden. This could be varied for specific applications as required.
The following search order simulates inheritance and could simply created by one API call setUpperTreeSearchPath:
0. a/b2/a/b0/c/F => match, stop 1. a/b2/a/b0/F 2. a/b2/a/F 3. a/F
This algorithm in particular could be repeated after the first match for the remaining upper tree again. This is either applied for a single search, or an iterator, where collections has to be processed.
0. a/b2/a/b0/c/F 1. a/b2/a/b0/F => match, stop 2. a/b2/a/F 3. a/F
- Next iteration, and so on...
0. a/b2/a/b0/c/F 1. a/b2/a/b0/F 2. a/b2/a/F => match, stop 3. a/F
This also works for side branches when the in memory string function is applied onto plist. Thus you can simply map e.g. the following branch by one call only:
a/b0/x/y/z/file.txt
- into:
/a/b2/a/b0/c/F | | V V =/=/ `-x/y/z/file.txt
The application of a low-level algorithm on files and directories in particular provides for simplified drop-in designs, with generic determination of application features. It is in particular possible to design quite powerful applications by just a few interface conventions. The provided library provides various parameters for the algorithm including reversed order, pattern match, and match-index based search.
A more complex application of this is Python itself, whereas a ligthweight application for bash scripts is presented by the project
bash-core-lib - https://sourceforge.net/p/bashcorelib/
bash-core - https://sourceforge.net/projects/bash-core/
which basically introduces OO elements and reusability by repositories into bash scripting based on ShellScriptlets and dotted object-tree-like notation.
Filesystems - Native and Standard Features¶
The path syntax elements supported by this module represent an abstraction, but finally rely on the supported platforms. Therefore internally the function ‘os.path.normpath’ is widely applied for the transformation of the native syntax elements into the internal canonical representation for processing. In addition in internal cases of textual syntax processing escaping may be occasianlly required.
In cases where special semantic treatment of the path elements is required, these could be activated or disabled by parameters of the call interface.
The following list depicts shortly the relevant standards and common APIs for the naming and namebinding of filesystem nodes, including some network aspects for specific filesystems like NFS, and SMB/CIFS.
The focus is the local filesystem, therefore elements dealing with local paths are managed. But it is still required to define the interface for cases where other address conventions are supplied.
- URIs based on RFC3986 for local files are resolved to
PWD=/call/position/ file:///local/filesystem/path => /local/filesystem/path
- When this is literally a valid filename, the following could be applied
PWD=/call/position/ ./file:///local/filesystem/path => /call/position/file:/local/filesystem/path
Linux and UNIX:
- IEEE Std 1003.1(TM), 2013 Edition; Chapter 4.12
//hostname/local/filesystem/path
The current version treats this literally, as a pathname, thus normally fails. The caller has to provide appropriate local filenames to local only interfaces.
REMARK: When introducing remote filesystem support, this will be adapted.
The behaviour could be changed by call parameter.
- Ignore
//hostname/local/filesystem/path => /hostname/local/filesystem/path
SMBFS:
The anononymous case of SMB/CIFS without required authentication is handled by the case depicted before.
The additional cases where additional hostname parameters are reuquired are following in a later step.
Microsoft(TM) Windows:
- Network shares
\\hostname\local\filesystem\path
Similar behaviour as depicted before for the compliance to the IEEE-1003.1 standard.
The behaviour could be changed by call parameter.
- Ignore
\\hostname\local\filesystem\path => \hostname\local\filesystem\path
Mac-OS:
- Current same as for Linux/Unix.
- Any other input format is simply ignored, and may lead to unpredictable behaviour. E.g.
http://path/name => http:/path/name
Because this could actually be a valid local filename.
Syntax Elements¶
The syntax elements for the normalization of pathnames are in particular essential for the treatment of the filesystem structure as a class and object hierarchy. Thus the behaviour has to be defined thoroughly from the beginning, even or better in particular in case of the foreseen evolutionary add-on extension.
The current release provides the following syntax, successive compatible extensions are going to follow soon. These the processing of the provided syntax is designed in two layers in accordance to common examples.
The lower layer provides the syntax elements to construct a pathname for local access, whereas the upper layer provides the information for the location of remote filesystems.
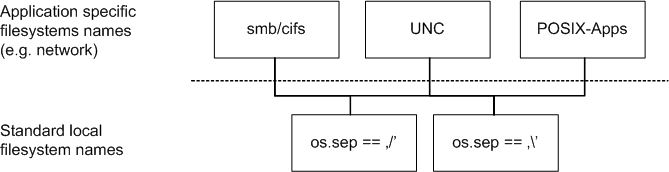
Thus the functions of the lower layer:
are similar to the system function ‘os.path.normpath’, Whereas the functions of the upper layer:
Assembles a tuple of components into a path name for access.
The escape and unescape funtions work basically similar to ‘os.path.normpath’. The behaviour is:
-
Escape backshlashes only, consider specific control characters recognized by the ‘re’ module. Any arbitrary number of seperator characters are normalized appropriately, including shares.
-
Unescape, this simply reverses the escape of a single character. Thus in particular the eventual normalization of ‘escapeFilePath’ for multiple present seperators is not reverted.
The following function hierarchy for pathname conversion including UNC, SMB, POSIX-Apps, and local filenames is supported.
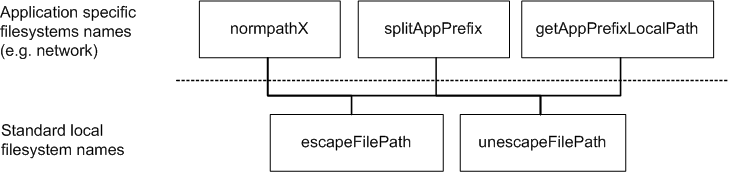
Anyhow, due to some specific poosition dependent interpretation of the ‘os.sep’ the lower layer has encoded the app specific knowledge into the ‘escapeFilePath’ routine. This also normalizes the ‘os.sep’ by conversion and elimination of neutral repetitons as well as special semantics of ‘.’ and ‘..’
- A single pathname is hereby represented by the syntax, where ‘cifs==smb’:
filesystemNodeName := ( pathname + SEP + filename | pathname [ + SEP ] | [ SEP ] + filename | SEP ) pathname := [ PREFIXKEY ] + dirname [ + SEP + pathname ] dirname := <valid-name-of-dir-node> filename := <valid-name-of-file-node> <valid-name-of-dir-node> := <valid-name-of-dir-node> [ + SEP$ ] PREFIXKEY := ( 'file:///' + 2SEP + SPECIALNODE + varSEP + share-name | 'file://' | 'smb://' + SPECIALNODE + varSEP + share-name | DRV | 2SEP SPECIALNODE [varSEP] | nSEP ) DRV := [a-z] + ':' # On MS-Windows SPECIALNODE := ( <networknode-access> ) share-name := ( 1*80pchar # see [MS-DTYP] ) <networknode-access> := [^SEP]+ varSEP := ( '' | 1SEP | 2SEP | nSEP ) 1SEP = ^SEP + !SEP 2SEP = ^SEP + SEP + !SEP # in accordance to IEEE Std 1003.1 and/or CIFS/SMB nSEP = ^SEP + SEP + SEP + SEP* # more than 2xSEP SEP := <OS-specific-seperator> <OS-specific-seperator> := ( '/' | '\' ) # for now only two are known SPECIAL_SYNTAX_DIAGRAM_CHARS_AND_REGEXPR := { '^', '$', '!', '+', '{', '}', '[', ']', ':=', '|', '<', '>', '#' }
The seperator commonly used in this document is ‘/’. This could be interchaned by the seperator ‘\’, which also defines an escape character, thus is omitted when not required.
The above syntax definition provides just a subset but very common set of possible naming schemes, additional may be supported in future versions.
For further details refer to:
- UNC: Common definition in [MS-DTYP]: Windows Data Types - Chap. 2.2.57 UNC; Microsoft Inc.
UNC = "\\" host-name "\" share-name [ "\" object-name ] host-name = "[" IPv6address ‘]" / IPv4address / reg-name ; IPv6address, IPv4address, and reg-name as specified in [RFC3986] share-name = 1*80pchar pchar = %x20-21 / %x23-29 / %x2D-2E / %x30-39 / %x40-5A / %x5E-7B / %x7D-FF object-name = *path-name [ "\" file-name ] path-name = 1*255pchar file-name = 1*255fchar [ ":" stream-name [ ":" stream-type ] ] fchar = %x20-21 / %x23-29 / %x2B-2E / %x30-39 / %x3B / %x3D / %x40-5B / %x5D-7B / %x7D-FF stream-name = *schar schar = %x01-2E / %x30-39 / %x3B-5B /%x5D-FF stream-type = 1*schar
- file://: The file URI Scheme - draft-kerwin-file-scheme-13; IETF
file-URI = f-scheme ":" f-hier-part [ "?" query ] f-scheme = "file" f-hier-part = "//" auth-path / local-path auth-path = [ f-auth ] path-absolute / unc-path / windows-path f-auth = [ userinfo "@" ] host local-path = path-absolute / windows-path unc-path = 2*3"/" authority path-absolute windows-path = drive-letter path-absolute drive-letter = ALPHA [ drive-marker ] drive-marker = ":" / "|"
smb://: [MS-SMB]: Server Message Block (SMB) Protocol; Microsoft Inc. The current implemented name resolution is a limited version of the file scheme. Thus based on “SMB File Sharing URI Scheme - draft-crhertel-smb-url-07”. This is outdated, but for now the first attempt for start.
smb_URI = ( smb_absURI | smb_relURI ) smb_absURI = scheme "://" smb_service [ "?" [ nbt_context ] ] smb_relURI = abs_path | rel_path scheme = "smb" | "cifs" smb_service = ( smb_browse | smb_net_path ) smb_browse = [ smb_userinfo "@" ] [ smb_srv_name ] [ ":" port ] [ "/" ] smb_net_path = smb_server [ abs_path ] smb_server = [ smb_userinfo "@" ] smb_srv_name [ ":" port ] smb_srv_name = nbt_name | host nbt_name = netbiosname [ "." scope_id ] netbiosname = 1*( netbiosnamec ) *( netbiosnamec | "*" ) netbiosnamec = ( alphanum | escaped | ":" | "=" | "+" | "$" | "," | "-" | "_" | "!" | "~" | "'" | "(" | ")" ) scope_id = domainlabel *( "." domainlabel ) smb_userinfo = [ auth_domain ";" ] userinfo_nosem auth_domain = smb_srv_name userinfo_nosem = *( unreserved | escaped | ":" | "&" | "=" | "+" | "$" | "," ) nbt_context = nbt_param *(";" nbt_param ) nbt_param = ( "BROADCAST=" IPv4address [ ":" port ] | "CALLED=" netbiosname | "CALLING=" netbiosname | ( "NBNS=" | "WINS=" ) host [ ":" port ] | "NODETYPE=" ("B" | "P" | "M" | "H") | ( "SCOPEID=" | "SCOPE=" ) scope_id )
cifs://: [MS-CIFS]: Common Internet File System (CIFS) Protocol; Microsoft Inc.
For now see SMB.
This syntax represents e.g. the following valid filepathanmes with the current position(PWD) as reference point for relative positions. For the conversion API refer to splitAppPrefix [docs] [source] and getAppPrefixLocalPath [docs] [source] :
/local/path/access
- Where the following equivalent transformations result
/local/path/access/dir/ => /local/path/access/dir/ # forces a directory /local/path/access/dir => /local/path/access/dir # could be a file too ./dir/ => /local/path/access/dir/ # forces a directory ./dir => /local/path/access/dir # could be a file too ../dir/ => /local/path/dir/ # forces a directory ../dir => /local/path/dir # could be a file too dir/ => /local/path/access/dir/ # forces a directory dir => /local/path/access/dir # could be a file too
- Where the following basic paths are equivalent
/local/path/access/dir/ == /local////////path/access//dir///// /local/path/access/dir/ == /local//.///./././path/access//dir//./.// /local/path/access/dir/ == /local//../path/////path/access/../../path/access/dir///// /local/path/access/dir != /local////////path/access//dir///// /local/path/access/dir != //local////////path/access//dir///// /local/path/access/dir != //local////////path/access//dir
- Where the following basic URI paths are still equivalent
file:///local/path/access/dir/ == /local////////path/access//dir///// file:///local/path/access/dir/ == /local//.///./././path/access//dir//./.// file:///local/path/access/dir/ == /local//../path/////path/access/../../path/access/dir///// file:///local/path/access/dir != file:///local////////path/access//dir///// file:///local/path/access/dir != //local////////path/access//dir///// file:///local/path/access/dir != //local////////path/access//dir
- Same for the first basic URI paths on both sides
file:///local/path/access/dir/ == file:///local////////path/access//dir///// file:///local/path/access/dir/ == file:///local//.///./././path/access//dir//./.// file:///local/path/access/dir/ == file:///local//../path/////path/access/../../path/access/dir///// file:///local/path/access/dir != file:///local////////path/access//dir/////
But for the last two no longer, because ‘2SEP’ has to be at the beginning of the string, which is interpreted here as the beginning of the raw string representation
file:///local/path/access/dir == file:////local////////path/access//dir///// file:///local/path/access/dir == file:////local////////path/access//dir #REMARK: Looking forward for qualified review comments!!!
Variants of Pathname Parameters - Literals, RegExpr, and Glob¶
The common variants of pathnames as parameters are provided by one of the categories:
Literal - literal names
The applicability varies on the scope. Whereas literals could be applied in any scope, these are the least flexible search pattern. These just provide native matches either on single nodes, or single goups in case of directories represented as containers.
Regular Expression - specific match pattern, which are implementation dependent
The regular expressions in general are part of applications, either special autonomous conversion filters, or embedded into a greater application, and/or programming environment.
These are strongly implementation dependent, even though a broad commen set is generally provided. These in particular lack the native support of filesystems, thus could be only used as input and/or output filters.
Glob - platform dependent native filesystem match
The ‘glob’ expressions are a very basic type of regular expressions, which are platform dependent. These could be applied at the interface of the filesystems, and influence the responce of the filesystem interface directly.
Semi-Literal - literal names combined with glob, or regexpr
The pathnames are internally processed depending on the category of the interface. Interfaces operating in memeory on strings only apply regular expressions, The implementation of interfaces accessing fthe filesystem, e.g. for existence tests and name resolution, use literal matches and glob.
The Semi-Literal type arose from the design, that ‘glob’ and ‘regexpr’ must not be intermixed because of the possible ambiguities. One of the main differences is the scope of match. The ‘glob’ functions are aware of seperators, for regexpr they represent simply a character. The pattern has some differences too, e.g.
regexpr: F[0-2]* := (F, F0, F1, F2, ) glob: F[0-2]* := (F.*, F0.*, F1.*, F2.*, )
So this basicly also prohibits functions like ‘fnmatch.translate()’ on intermixed expressions. Anyhow, the user could prepare a string as regexpr before calling the interface. But be aware, for filesystem evaluation the glob-style is applied only.
Literals and one only of the pattern types could be intermixed arbitrarily.
The implementation and the possible intermix are provided due to the implemented algorithm when the following is true:
‘regexpr’ and ‘glob’ could be intermixed, when the ‘glob’ compiled by ‘re’ does not match. Than the algorithm keeps it simply as an unknown node, and continues with ‘glob’ expansion. Thus the following strict pattern of path names is provided, where the order is significant:
<mixed-regexpr-glob> := <literal-or-regexpr><literal-or-glob>
The rule of thumb is given by the following combinations:
- literal + glob:
a literal path part matching the search path, a glob to be applied to the filesystem.
- regexpr + literal:
a regexpr to be applied onto the in-memory path, followed by a literal applicable in any case.
- literal + regexpr + literal + glob + literal:
this order is provided by the algorithm but the input pattern is not verified to be of a consistent type and though the applicability of the syntax has to be assured by the caller
The overall applicability for specific execution and call contexts is depicted in the following table.
| Application Processing Scope | Literals | Semi-Literals | RegExpr | glob |
|---|---|---|---|---|
| In-Memory Path Strings | yes | yes | yes | no (1) |
| Filesystem | yes | yes | no | yes |
- is treated as an ‘regexpr’, when matches this is resolved, else ends re-processing and is applied as a ‘glob’
Thus the application of RegExpr is implemented as an optional parameter performed on in.memory strings only. Therefore a multi-level approach is reuqired [API] [UseCases] when these has to be applied onto the results of a filesystem search. The workflow in case of required searches for unknown filesystem nodes by re-patterns is:
- filter and collect filesystem entries by ‘literal’ and ‘glob’ parameters
- post-filter the collected set by ‘literal’ and ‘RegExpr’ type parameters.
Call Parameters of the API¶
The call interface provides for groups of functions and classes with a set of common parameters and additional context specific modifications.
The provided function sets comprise the categories:
- Filesystem Positions and Navigation
- Canonical Node Address - Current: Experimental / Non-Productive
For the list of the interfaces refer to [API].
Canonical Node Address¶
- For now experimental and non-productive, for review and comments [API]:
filesysobjects.NetFiles.normpathX
For syntax design requirements refer to “Extended Filesystems - Network Features”.
See also Python issue:
- Issue 26329: os.path.normpath(“//”) returns // - http://bugs.python.org/issue26329
