Routing Topologies¶
Below are a few examples of routing topologies.
Of course you can design routing topologies to suit your application using elements from any of the models below.
Remote Procedure Call (RPC)¶
AMQP can be used to create a remote procedure call system, where remote method calls are sent as AMQP messages. These messages are routed to appropriate “request queues” on which the handlers are listening. The requester needs no knowledge of the number or the location of these handlers, so the requester is decoupled from the handlers, and the handlers can be reconfigured with no changes to the requesting service.
A disadvantage is that the requester can be kept waiting if the handler does not put a result into the result queue, perhaps because it has hung or crashed, etc. The requester would need appropriate timeouts, etc.
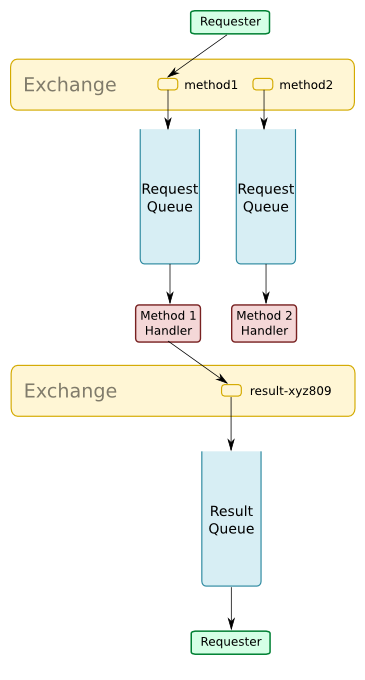
Availability and load sharing can be achieved simply by adding more handlers, as decribed in the Task Distribution pattern below.
Suggested Settings:
- Result queue could be declared exclusive and auto_delete.
- The client could opt to omit the result queue name, so it will be automatically generated by the server.
- The result queue name could be specified in the reply_to message property.
- Request could be published as immediate and mandatory, so that it will be returned if the message is not routed or immediately consumed.
- Messages could be published as non-persistent - this gives better throughput, as the message doesn’t have to be written to disk. This may be important.
Map-Reduce¶
We can modify the RPC model such that instead of a job going to one particular worker, it instead goes to many workers that each have a partial data set or particular responsibility for part of a task.
When a job is submitted it is received by each one of a number of shards. Each shard computes a result, which is put into a result queue. A reducer service can combine these results.
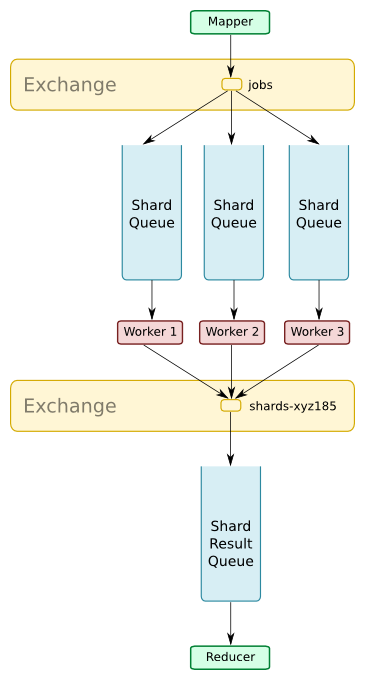
If necessary, the combined result might be put into another queue to be returned to the original requester.
Suggested Settings:
With this configuration the developer must choose how to deal with missing workers.
- If partial results are useful, and response time is more important than completeness, the reducer doesn’t need to wait for all mappers to finish. It could wait for a fixed time and discard any results that arrive too late. We could use non-persistent delivery modes and optimise for performance, as with the simple RPC above.
- If complete results are important, and perhaps if computation is very expensive, then we might want to ensure message delivery is reliable, so that no job is ever lost and no computed result is ever dropped. However, this requires the reducer to be more complicated, as it will need to persist all partial results until a missing worker is restored.
- In the diagram above, I’ve used a fanout-style exchange, which is suitable if we assume all workers can compute a partial and independent result for the job. We might instead use a direct exchange, with the mapper service deciding how to partition the job and presenting partial jobs direct to workers.
Task Distribution¶
If the problem involves intensive tasks we can spread them over a cluster of machines. This allows machines to be added to the cluster elastically to deal with load spikes.
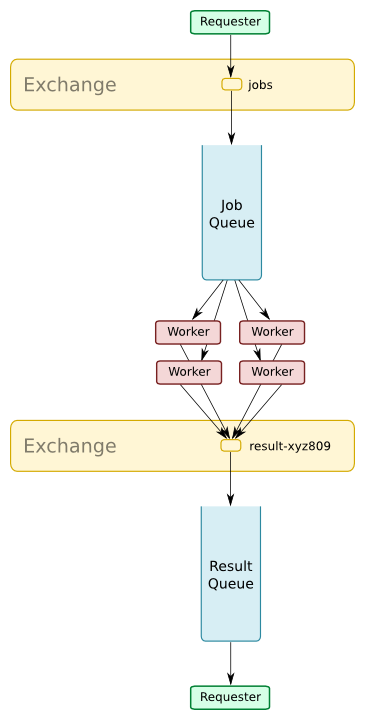
Often we don’t need to send results back to the original producer: it may be sufficient to simply record them to a database or filesystem to be retrieved at a later time.
Suggesting settings would be similar to the map-reduce pattern described above.
Publish-Subscribe¶
The Publish-Subscribe (Pub-Sub) pattern can be used to loosely couple arbitrary services. Perhaps we have a number of services that generate events, and a variety of consumers that need to receive some subset of those events to stay in sync or to take some other action.
The pub-sub pattern is useful because the consumer is responsible for registering to receive the events it is interested in. The publisher is responsible just for making events available.
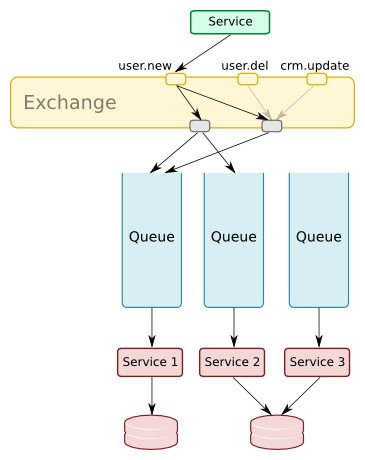
Suggested settings:
- Topic exchanges are particularly useful in this case, to allow the consumers the flexibility to choose the messages to receive based on a routing key pattern.
- Because we want reliable eventual consistency we need to use reliable publishing. This would entail making the queues and exchanges durable, and publishing each message as persistent.
- We might also want to use transactions or publish confirmation to ensure errors are raised if publishing is unsuccessful.
- We can’t use the immediate or mandatory flags, because we don’t know about the consumers of our messages.