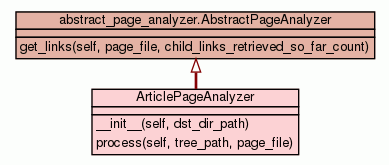
|
Process the node (normally, this method is called once for every
node).
- Parameters:
tree_path - path to the tree node the navigator is currently in i.e.
subsequent node names from the tree root to the current node.
This might be e.g. ["root"] for a path to
the root node or ["root",
"magazine-2011-09-18", "article_23"]
for some other node inside the tree hierarchy.page_file - file-like structure to be processed - Overrides:
abstract_page_analyzer.AbstractPageAnalyzer.process
- (inherited documentation)
|