Retrieving data using Python¶
This tutorial will cover how to retrieve data from a sMAP archiver using Python. We will use the http://www.openbms.org/ site as an example data source; feel free to run these queries yourself! Before reading this, it will be helpful to have familiarized yourself with Key Concepts as well as followed the instructions for sMAP Library Installation.
Setup¶
You can download a working copy of this example, and then follow along with the explanation.
Client bindings for the sMAP archiver are available in the smap.archiver.client package. To set one up, all you need is the following header:
from smap.archiver.client import SmapClient
c = SmapClient("http://www.openbms.org/backend")
Basic access by UUID¶
Once you’ve got a client, you can start to retrieve data. In the simplest form of access, you already know the UUIDs of the streams you’re interested in. If you have that, you can access directly by range-query. The data retrieval method expects the range to be supplied in the form of Unix timestamps; the smap.contrib.dtutil module contains several convenience functions for manipulating datetime‘s in different time zones:
from smap.contrib import dtutil
start = dtutil.dt2ts(dtutil.strptime_tz("1-1-2013", "%m-%d-%Y"))
end = dtutil.dt2ts(dtutil.strptime_tz("1-2-2013", "%m-%d-%Y"))
oat = [
"395005af-a42c-587f-9c46-860f3061ef0d",
"9f091650-3973-5abd-b154-cee055714e59",
"5d8f73d5-0596-5932-b92e-b80f030a3bf7",
"ec2b82c2-aa68-50ad-8710-12ee8ca63ca7",
"d64e8d73-f0e9-5927-bbeb-8d45ab927ca5"
]
data = c.data_uuid(oat, start, end)
data is returned as a list of numpy matrices. Each element corresponds to the uuid in the oat list, and has two columns: the first is timestamp (in unix-time milliseconds) and the second has data values.
Query options¶
There are two optional query arguments to data_uuid: cache, and limit. Using limit, you can restrict the number of points returned for each timeseries to a maximum; this can be useful to prevent returning unexpectedly large datasets.
By default, the client library will cache all data downloaded in the .cache directly; subsequent downloads of the same time range will consult this local data rather than the server. If you wish to avoid this cache, you can pass cache=False to the library.
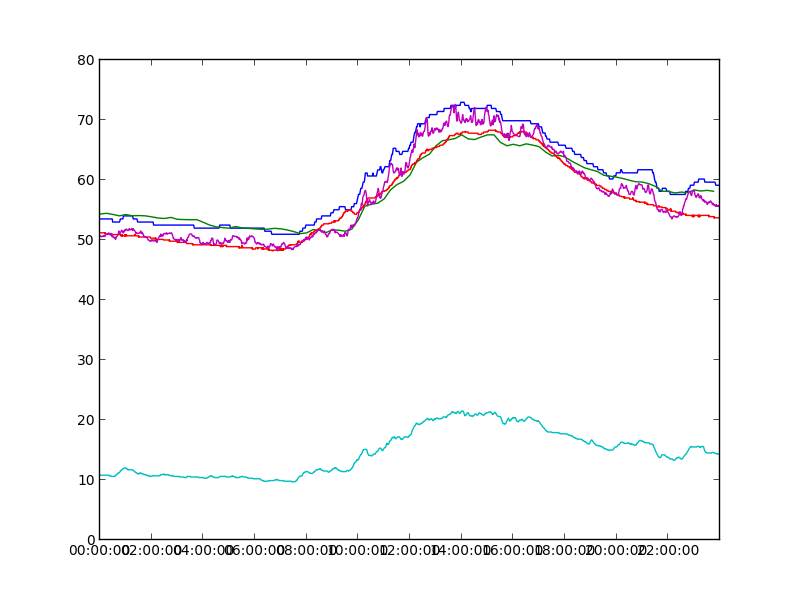
Plotting this data¶
Making a time-series plot in matplotlib might be the next thing you want to do. It expects a slightly different date format than sMAP uses; matplotlib.dates contains the right conversion utilities.
Continuing the previous example:
from matplotlib import pyplot, dates
for d in data:
pyplot.plot_date(dates.epoch2num(d[:, 0] / 1000), d[:, 1], '-',
tz='America/Los_Angeles')
pyplot.show()
Access by sMAP Query¶
The archiver also includes a Query Language, which allows SQL-like queries on data metadata. Rather than hard-coding lists of time series UUIDS, you can instead retrieve data on the basis of tags. For instance, we could instead retrieve the weather data in the previous example using a tag query:
uuids, data = c.data("Metadata/Extra/Type = 'oat'", start, end)
The first argument to data is a where clause, restricting the set of time series returned to ones with appropriate tags. In this case, we know that the data we’re interested in is tagged with a Metadata/Extra/Type value set to oat.
In order to figure out which feed is which, we might instead want to retrieve the metadata for these streams. We can do this using the tags method:
tags = c.tags("Metadata/Extra/Type = 'oat'")
The metadata is returned as list of dict‘s of tags, which you can inspect and match up with with returned data using the uuids. A fully worked example puts this all together.
In order to explore what tags and values are available, you can try the stream status interface. This lets you explore the set of allowable tags and tag values using a graphical interface, and see some example data. Once you’ve located the data you’re interested in, you can either hard-code the UUIDs or encode that tag query directly into your application.
Additional Library Functionality¶
The client library contains several other methods for accessing data efficiently; for instance, you can get the latest data or access data relative to an reference timestamp.
- class smap.archiver.client.SmapClient(base='http://ar1.openbms.org:8079', key=None, private=False, timeout=50.0)[source]¶
- latest(where, limit=1, streamlimit=10)[source]¶
Load the last data in a time-series.
See prev for args.
- prev(where, ref, limit=1, streamlimit=10)[source]¶
Load data before a reference timestamp. For instance, to locate the last reading whose timestamp is less than the current time, you can use latest(where_clause, int(time.time()).
Parameters:
- next(where, ref, limit=1, streamlimit=10)[source]¶
Load data after a reference time.
See prev for args.
- data(where, start, end, limit=10000, cache=True)[source]¶
Load data for streams matching a particular query.
Parameters: Returns: a tuple of (uuids, data). uuids is a list of uuids matching the selector, and data is a list numpy matrices with the data corresponding to each uuid.
- data_uuid(uuids, start, end, cache=True, limit=-1)[source]¶
Low-level interface for loading a time range of data from a list of uuids. Attempts to use cached data and load missing data in parallel.
Parameters: Returns: a list of data vectors. Each element is numpy.array of data in the same order as the input list of uuids