Main window¶
Vaex can handle command line options to quickly open files and make plots, the syntax is:
vaex <filename> <expr1> <expr2> [name=value ...] - <expr3> <expr4>... -- <filename2> <expr5> <expr6>...
In short, start with a filename, then enter expressions (1 expression will open a histogram, 2 a density plot, 3 the volume rendering), optionally folowed by key value pairs to change the settings of the plot, plots are seperator by a minus sign ‘-‘, datasets are seperated by two minus signs ‘–’. Examples:
vaex mydataset.hdf5 x y # opens 1 plot
vaex mydataset.hdf5 x y amplitude="log(counts+1)" weight=temperature # one plot with modified setting
vaex mydataset.hdf5 x y - x z -- otherdataset.hdf5 teff logg - J-K M_J # two plots for one dataset, and two for a different dataset
Filename can be any of the supported filetypes. The (column) expression are the same as in the graphical interface.
Key, value pairs correspond to the GUI. For example, plotting the log of the average temperature with a different colormap:
vaex mydataset.hdf5 x y amplitude="log(counts+1)" weight=temperature colormap=afmhot
Possible options are:
- amplitude: grid expression, examples: “log(counts+1)”, “sqrt(counts)”, average**2 (NOTE: expressions that include parenthesis are enclosed in quotes to avoid the shell from interpreting them.
- weight: column expression for the weighted grid, if this is specified, also average is available as a grid (see grid expression). Examples are: weight=temperature, weight=vx**2
- vx, vy, vz: column expression for the x, y and z component of the vector field. Example: vx=vx vy=vy vy=vz
- colormap (or cmap, colourmap): name of the colormap, a list is visible in the GUI. Examples cmap=afmhot cmap=bwr, cmap=rainbow cmap=jet
- vz_colormap (or vz_cmap, vz_colourmap): colormap for the arrows for the vector field in a 2d view.
- xlim: limits for x axis. Example xlim=-10,10 xlim=40+5,50+5
- ylim: limits for y axis
- zlim: limits for z axis
- lim: sets all limits to the same value. Example: lim=-10,10 will set the x, y and possible the z limits
- aspect: sets the aspect of the plot, only aspect=1 is supported
- compact: removes many parts of the GUI apart from the plot, options are ‘normal’ and ‘ultra’. Examples: compact=normal compact=ultra
- grid_size: sets the size of the grid, possible options are 32,64,128,256,512 and 1024. Example grid_size=128
- grid_size_vector: similar but now for the vector field or othe overlays.
- selection: filename of a saved numpy array containing a boolean mask with the selection, this can be saved from the GUI. Example: selection=mydataset-selection.npy
- filename: filename for making a hardcopy of the plot directory, can also be done from the GUI.
- vr_quality: quality for the volume rendering, options are 0,1,2, where 0 is worst quality and best performance and 2 is best quality,
- page: Default tab page to open in the plot, options are “Main”, “Vector field”, “Transfer function”. Example: page=”Vector field”
Vaex supports SAMP to communicate and interoperate with other applications. Since vaex focusses on large datasets, the method of transferring data using VOTables is not recommended (although supported, it can be quite slow). For this example we assume that you have a working version of TOPCAT (version 4.2 was used at the time of writing) and that you have your dataset in both fits format (or any other format TOPCAT can read), and a hdf5 file (say mydata.fits and mydata.hdf5). Start TOPCAT with the SAMP hub enabled (the default in version 4.2), and open the fits file. Start vaex and open the hdf5 file. When vaex is started, it tries to connect to the SAMP hub directly, which you can verify by checking if connect icon in the toolbar  is selected, or the menu option “SAMP”->”Connect to SAMP hub” is checked. In case you started TOPCAT after you started vaex, you can connect to the SAMP hub using the connect icon
, or from the menu “SAMP”->”Connect to SAMP hub”. Now both TOPCAT and vaex are connected to the SAMP hub (which is started by TOPCAT), and should be able to send eachother messages.
is selected, or the menu option “SAMP”->”Connect to SAMP hub” is checked. In case you started TOPCAT after you started vaex, you can connect to the SAMP hub using the connect icon
, or from the menu “SAMP”->”Connect to SAMP hub”. Now both TOPCAT and vaex are connected to the SAMP hub (which is started by TOPCAT), and should be able to send eachother messages.
From SAMP, broadcast the table (mydata.fits) by clicking the broadcast icon 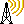 or from the menu “Interop”->”Send table to”->”vaex”. A popup should appear in vaex asking what it should do. The first option is to read the fits file (although vaex supports fits files, we don’t recommend using them, see filetypes <supported-files>). Another options is to download is as a VOTable (only do this for small datasets, max 100 000 rows). There should also be an option to link it to an existing open dataset, choose that option
or from the menu “Interop”->”Send table to”->”vaex”. A popup should appear in vaex asking what it should do. The first option is to read the fits file (although vaex supports fits files, we don’t recommend using them, see filetypes <supported-files>). Another options is to download is as a VOTable (only do this for small datasets, max 100 000 rows). There should also be an option to link it to an existing open dataset, choose that option

Options in vaex when a VOTable is broadcasted.
Now that TOPCAT and vaex are both connected to the SAMP hub and both datasets are ‘linked’, open the same or a simular plot in both topcat and vaex. Select the pick mode in vaex by clicking the pick icon in the toolbar |icon_pick|, or pressing ‘p’. Now pick an object/row, and it should be selected in both vaex and TOPCAT, as shown below.
Picking an object in vaex will also select it in TOPCAT.
To enable it visa versa, make sure that you select “Broadcast row” in TOPCAT’s main window.
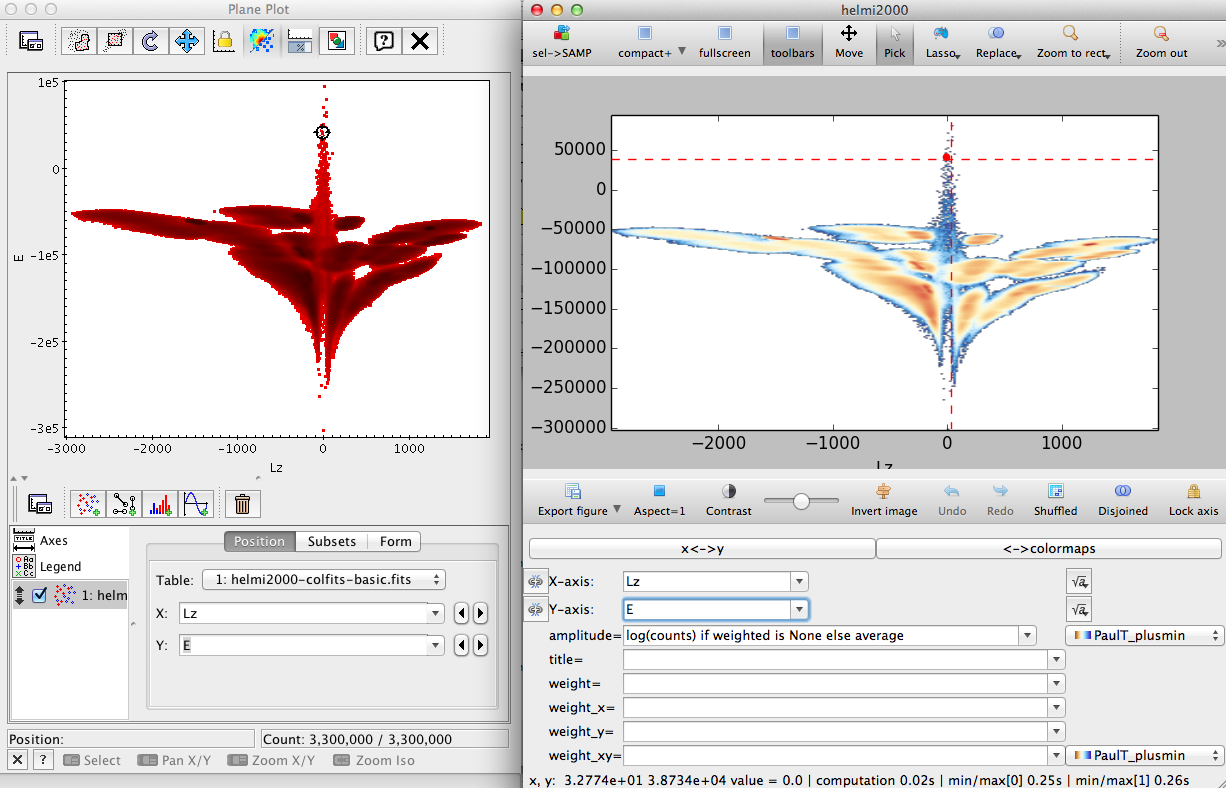
Now do a lasso selection in vaex, and click the ‘icon_samp_send’
Selections can be send from vaex to TOPCAT and visa versa.
To send a selection from TOPCAT, click the lasso icon in the toolbar, draw the region, click the icon again and choose “Transmit Subset”
The expressions for columns can are similar to mathematical expressions in most programming languages, examples are:
sqrt(x**2 + y**)
arctan2(y,x)
log(x+1)
A list of all mathematical functions can be found here: https://github.com/pydata/numexpr#supported-functions.
The expressions for grids are pure Python expressions. For the amplitude the following variables are available:
-counts: grid which contains the histogram counts for the columns. -weighed: sum of the quantity as given by the weight field. -average: weighted/counts where counts is greater than zero. This evaluates to the average of the quantity as given in the weight field. -peak_column: grid where column contains the peak value per column, giving by this grid sets the peak value of every column to 1, e.g: counts/peak_column, average/peak_column -peak_rows: similar, but now per row.
All functions in the numpy packages are available, where http://docs.scipy.org/doc/numpy/reference/routines.math.html describes the most useful. In addition, these functions are avaliable:
- gf: gaussian filter, example gf(log(counts+1),1.), alias to http://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.filters.gaussian_filter.html. Convolves the grid (first argument) with a multidimensional gaussian with a sigma given as second argument. Sigma is in pixel or voxel units, and if a number is given as argument it is taken for all the dimensions, gf(log(counts+1), [2.,1.]) will convolve with a gaussian which is wider in the vertical (y) direction.
Some examples are:
- log(counts) if weighted is None else average (default): this evaluates of counts if the expression ‘ weighted is None’ is True, otherwise average. This will then show the average when the weight field is filled in, otherwise log(counts)
- counts/peak_column
- clip(counts/counts/max(), 0, 1)
Supported filetypes are:
- hdf5: This fileformat is a hierarchical format, similar to html/xml, except that it can store data in native format. Since it is so flexible, there are no standard ways of how to store tabular data. We chose the following format:
- ‘/columns’ Under this group, we store all the columns
- example: ‘/columns/x’ This would be where a hdf5-dataset would be store for the columnname ‘x’, supported types are floats and integers.
The big advantage of using hdf5 is that the file can be memory mapped, meaning no copies of the data to main memory need to be made. This also makes it possible to use data that is larger than main memory.
- fits: Using the binary table extension, a fits file can store binary data. Fits however stores the data in big endian format, x86 cpus (intel, amd) use low endian format, this causes a small overhead for conversion. Also, storage is usually row based, which can lead to overhead in reading. Using TOPCAT’s colfits will give better performance, since this is uses column based storage. We recommend exporting to hdf5 using our program for beter performance.
- Gadget hdf5 file: File format of Gadget2, splitted files are not yet supported
- VOTable: Although supported, all records are kept in memory and read performance is quite poor. Only use this for small datasets, and otherwise export to hdf5