EdgeFrame assign_sample¶
-
assign_sample(self, sample_percentages, sample_labels=None, output_column=None, random_seed=None)¶ Randomly group rows into user-defined classes.
Parameters: sample_percentages : list
Entries are non-negative and sum to 1. (See the note below.) If the i‘th entry of the list is p, then then each row receives label i with independent probability p.
sample_labels : list (default=None)
Names to be used for the split classes. Defaults to “TR”, “TE”, “VA” when the length of sample_percentages is 3, and defaults to Sample_0, Sample_1, ... otherwise.
output_column : unicode (default=None)
Name of the new column which holds the labels generated by the function.
random_seed : int32 (default=None)
Random seed used to generate the labels. Defaults to 0.
Randomly assign classes to rows given a vector of percentages. The table receives an additional column that contains a random label. The random label is generated by a probability distribution function. The distribution function is specified by the sample_percentages, a list of floating point values, which add up to 1. The labels are non-negative integers drawn from the range
![[ 0, len(S) - 1]](../../../R_images/math/a714b05c510a3aa90290c5df30b0ac24159a7eb6.png) where
where 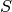 is the sample_percentages.
is the sample_percentages.Notes
The sample percentages provided by the user are preserved to at least eight decimal places, but beyond this there may be small changes due to floating point imprecision.
In particular:
- The engine validates that the sum of probabilities sums to 1.0 within eight decimal places and returns an error if the sum falls outside of this range.
- The probability of the final class is clamped so that each row receives a valid label with probability one.
Examples
Consider this simple frame.
>>> frame.inspect() [#] blip id ============= [0] abc 0 [1] def 1 [2] ghi 2 [3] jkl 3 [4] mno 4 [5] pqr 5 [6] stu 6 [7] vwx 7 [8] yza 8 [9] bcd 9
We’ll assign labels to each row according to a rough 40-30-30 split, for “train”, “test”, and “validate”.
>>> frame.assign_sample([0.4, 0.3, 0.3]) [===Job Progress===]
>>> frame.inspect() [#] blip id sample_bin ========================= [0] abc 0 VA [1] def 1 TR [2] ghi 2 TE [3] jkl 3 TE [4] mno 4 TE [5] pqr 5 TR [6] stu 6 TR [7] vwx 7 VA [8] yza 8 VA [9] bcd 9 VA
Now the frame has a new column named “sample_bin” with a string label. Values in the other columns are unaffected.
Here it is again, this time specifying labels, output column and random seed
>>> frame.assign_sample([0.2, 0.2, 0.3, 0.3], ... ["cat1", "cat2", "cat3", "cat4"], ... output_column="cat", ... random_seed=12) [===Job Progress===]
>>> frame.inspect() [#] blip id sample_bin cat =============================== [0] abc 0 VA cat4 [1] def 1 TR cat2 [2] ghi 2 TE cat3 [3] jkl 3 TE cat4 [4] mno 4 TE cat1 [5] pqr 5 TR cat3 [6] stu 6 TR cat2 [7] vwx 7 VA cat3 [8] yza 8 VA cat3 [9] bcd 9 VA cat4