Glossary¶
- Adjacency List
A representation of a graph as a list. Each line of the list consists of a unique vertex identification, and a list of all of that vertex’s neighboring vertices.
Example:
Node Connection List /------------------------/ A B, D B A, C, D C B D A, B
- Aggregation Function
A mathematical function which is usually computed over a single column. Supported functions:
- avg : The average (mean) value in the column
- count : The count of the rows
- count_distinct : The count of unique rows
- max : The largest (most positive) value in the column
- min : The least (most negative) value in the column
- stdev : The standard deviation of the values in the column, see Wikipedia: Standard Deviation
- sum : The result of adding all the values in the column together
- var : The variance of the values in the column, see Wikipedia: Variance and Bias vs Variance
- Alpha
- See API Maturity Tags.
- Alternating Least Squares
A method used in some approaches to multidimensional scaling, where a goodness-of-fit measure for some data is minimized in a series of steps, each involving the application of the least squares method of parameter estimation.
See the API section on the Collaborative Filter Model for an in-depth discussion of this method.
Functions in the API may be at different levels of software maturity. Where a function is not mature, the documentation will note it with one of the following tags. The absence of a tag means the function is standardized and fully tested.
[ALPHA] Indicates a function or feature which has been developed, but has not been completely tested. Use this function with caution. This function may be changed or eliminated in future releases.
[BETA] Indicates a function or feature which has been developed and preliminarily tested, but has not been completely tested. Use this function with caution. This function may be changed in future releases.
[DEPRECATED] Indicates a function or feature which is no longer supported. It is recommended that an alternate solution be found. This function may be removed in future releases.
- Arity
- In logic, mathematics, and computer science, the arity of a function or operation is the number of arguments or operands the function or operation accepts.
- ASCII
- Abbreviated from American Standard Code for Information Interchange, ASCII is a character-encoding scheme. Originally based on the English alphabet, it encodes 128 specified characters into 7-bit binary integers.
- Average Path Length
- In network topology, the average number of steps along the shortest paths for all possible pairs of vertices.
- Bayesian Inference
A probabilistic graphical model representing the conditional dependencies amongst a set of random variables with a directed acyclic graph.
Contrast with Markov Random Fields
For more information, see Wikipedia: Bayesian Network.
- Belief Propagation
- See Loopy Belief Propagation.
- Beta
- See API Maturity Tags.
- Bias vs Variance
- In this context, “bias” means accuracy, while “variance” means accounting for outlier data points.
- Bias-variance trade-off
- In supervised classifier training, the problem of minimizing two sources of prediction error: erroneous assumptions in the learning algorithm, and sensitivity to small details in the training data (in other words, over-fitting) when generalizing to a testing data set.
- Central Tendency
- A typical value for a probability distribution. It may also be called a center or location of the distribution. Colloquially, measures of central tendency are often called averages.
- Centrality
From Wikipedia: Centrality:
In graph theory and network analysis, centrality of a vertex measures its relative importance within a graph. Applications include how influential a person is within a social network, how important a room is within a building (space syntax), and how well-used a road is within an urban network. There are four main measures of centrality: degree, betweenness, closeness, and eigenvector. Centrality concepts were first developed in social network analysis, and many of the terms used to measure centrality reflect their sociological origin. [8]- Centrality (Katz)
- See Katz Centrality.
- Centrality (PageRank)
- See Centrality.
- Character-Separated Values
- A file containing tabular data (numbers and text) in plain-text form. The file can consist of any number of records, separated by a unique character. New line characters are usually used for this purpose. Each record consists of one or more fields, separated by some unique character. Commas are usually used for this purpose. Tab characters are also quite common.
- Classification
- The process of predicting category membership for a set of observations based on a model learned from the known categorical groupings of another set of observations.
- Clustering
- See Collaborative Clustering.
- Collaborative Clustering
- The unsupervised grouping of observations based on one or more character traits.
- Collaborative Filtering
- The process of filtering for information or patterns using techniques involving collaboration among multiple agents, viewpoints, data sources, etc. [4]
- Comma-Separated Variables
- See Character-Separated Values.
- Community Structure Detection
- For complex networks, the process of identifying vertices that can be easily grouped into densely-connected sub-groupings.
- Confusion Matrices
- Plural form of Confusion Matrix
- Confusion Matrix
- In machine learning, a table describing the performance of a supervised classification algorithm, in which each column corresponds to instances of a predicted class, while each row represents the instances of the true class. Also known as contingency table, error matrix, or misclassification matrix.
- Conjugate Gradient Descent
Trusted Analytics Platform implements this algorithm. Specifically, it uses CGD with bias for collaborative filtering.
For more information: Factorization Meets the Neighborhood (pdf) (see equation 5).
- Connected Component
- In graph theory, a sub-graph in which any two vertices are interconnected but share no connections with other vertices in the sub-graph.
- Convergence
Where a calculation (often an iterative calculation) reaches a certain value.
For more information see: Wikipedia: Convergence (mathematics).
- CSV
- See Character-Separated Values
- Degree
The degree of a vertex is the number of edges incident to the vertex. Loops are counted twice. The maximum and minimum degree of a graph are the maximum and minimum degree of its vertices.
For more information see: Wikipedia: Degree (graph theory).
- Deprecated
- See API Maturity Tags.
- Directed Acyclic Graph (DAG)
In mathematics and computer science, a graph formed by a collection of vertices and directed edges, each edge connecting one vertex to another, such that there is no way to start at some vertex
 and follow a sequence of edges that eventually loops back to
again.
and follow a sequence of edges that eventually loops back to
again.Contrast with Undirected Graph.
- ECDF
- See Empirical Cumulative Distribution
- Edge
- A connection — either directed or not — between two vertices in a graph.
- Empirical Cumulative Distribution
 is a step function with jumps
is a step function with jumps 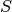 at
observation values, where
at
observation values, where 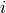 is the number of tied observations
at that value.
Missing values are ignored.
is the number of tied observations
at that value.
Missing values are ignored.For observations
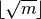 ,
is the fraction of observations less than or
equal to
,
is the fraction of observations less than or
equal to  .
.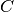
where
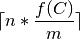 is the indicator of event
is the indicator of event 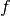 .
For a fixed , the indicator
.
For a fixed , the indicator 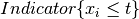 is a Bernoulli random variable with parameter
is a Bernoulli random variable with parameter 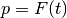 , hence
, hence
 is a binomial random variable with mean
is a binomial random variable with mean
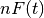 and variance
and variance 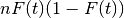 .
This implies that is an unbiased estimator for
.
This implies that is an unbiased estimator for
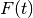 .
.- Enumerate
- Verb — To specify each member of a sequence individually in incrementing order.
- Equal Depth Binning
- Equal depth binning places column values into groups such that each group contains the same number of elements.
- Equal Width Binning
- Equal width binning places column values into groups such that the values in each group fall within the same interval and the interval width for each group is equal.
- Extract, Transform, and Load
From Wikipedia: Extract, Transform, and Load:
In computing, ETL refers to a process in database usage and especially in data warehousing that:
- Extracts data from outside sources
- Transforms it to fit operational needs, which can include quality levels
- Loads it into the end target (database, more specifically, operational data store, data mart, or data warehouse)
ETL systems are commonly used to integrate data from multiple applications, typically developed and supported by different vendors or hosted on separate computer hardware. The disparate systems containing the original data are frequently managed and operated by different employees. For example a cost accounting system may combine data from payroll, sales and purchasing.
- F-Measure
- In machine learning, a metric that quantifies a classifier’s accuracy. Traditionally defined as the harmonic mean of precision and recall. Also known as F1 score.
- F-Score
- See F-Measure.
- F1 Score
- See F-Measure.
- float32
- A real number with 32 bits of precision.
- float64
- A real number with 64 bits of precision.
- Frame (capital F)
- A table database with rows and columns containing data.
- A class object with the functionality to manipulate the data in a frame.
- GaBP
- See Gaussian Belief Propagation.
- Gaussian Belief Propagation
- A special case of belief propagation when the underlying distributions are Gaussian (Weiss & Freeman [9]).
- Gaussian Distribution
Normal Distribution A group of values, where the probability of any specific value:
- will fall between two real limits,
- is evenly centered around the mean,
- approaches zero on either side of the mean.
A Gaussian distribution is defined as:
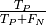
 is the mean of the distribution.
is the mean of the distribution.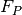 is the standard deviation.
is the standard deviation.
- Gaussian Random Fields
- A random group of vertices displaying a Gaussian distribution of one or more sets of properties.
- Global Clustering Coefficient
The global clustering coefficient is based on triplets of vertices. A triplet consists of three vertices that are connected by either two (open triplet) or three (closed triplet) undirected edges. A triangle consists of three closed triplets, one centered on each of the vertices. The global clustering coefficient is the number of closed triplets (or 3 x triangles) over the total number of triplets (both open and closed).
For more information see: Wikipedia: Global Clustering Coefficient.
See also Local Clustering Coefficient.
- Graph
A representation of a set of vertices, where some pairs of objects are connected by edges. The links that connect some pairs of vertices are called edges. Typically, a graph is depicted in diagrammatic form as a set of dots for the vertices, joined by lines or curves for the edges. Graphs are one of the objects of study in discrete mathematics.
For more information see: Wikipedia: Graph (mathematics).
- Graph Analytics
The broad category of methods used to examine the statistical and structural properties of a graph, including:
- Traversals – Algorithmic walk-through of the graph to determine optimal paths and relationship between vertices.
- Statistics – Important attributes of the graph such as degrees of separation, number of triangular counts, centralities (highly influential nodes), and so on.
Some are user-guided interactions, where the user navigates through the data connections, others are algorithmic, where a result is calculated by the software.
Graph learning is a class of graph analytics applying machine learning and data mining algorithms to graph data. This means that calculations are iterated across the nodes of the graph to uncover patterns and relationships. Thus, finding similarities based on relationships, or recursively optimizing some parameter across nodes.
For more information, see the article Graph Analytics by Pak Chung Wong.
- Graph Database Directions
As a shorthand, graph database terminology uses relative directions, assumed to be from whatever vertex you are currently using. These directions are:
- left: The calling frame’s index
- right: The input frame’s index
- inner: An intersection of indexes
So a direction like this: “The suffix to use from the left frame’s overlapping columns” means to use the suffix from the calling frame’s index.
- Graph Element
- A graph element is an object that can have any number of key-value pairs, that is, properties, associated with it. Each element can have zero properties as well.
- HBase
- Apache HBase is the Hadoop database, a distributed, scalable, big data store.
- Hyperparameter
Parameter that describe the prior distribution (the assumption about the data before observing it) as opposed to the parameters that govern the underlying system.
In particular, for Latent Dirichlet Allocation:
Alpha is the parameter of the Dirichlet “prior” on the per-document distribution of words. In other words, how the distribution of words per document is modeled before seeing any data.
Beta is the parameter of the Dirichlet “prior” on the per-topic word distribution. In other words, how the distribution of words per topic is modeled before seeing any data.
- int32
- An integer is a member of the set of positive whole numbers {1, 2, 3, . . . }, negative whole numbers {-1, -2, -3, . . . }, and zero {0}. Since a computer is limited, the computer representation of it can have 32 bits of precision.
- int64
- An integer is a member of the set of positive whole numbers {1, 2, 3, . . . }, negative whole numbers {-1, -2, -3, . . . }, and zero {0}. Since a computer is limited, the computer representation of it can have 64 bits of precision.
- Ising Smoothing Parameter
The smoothing parameter in the Ising model. For more information see: Wikipedia: Ising Model.
You can use any positive float number, so 3, 2.5, 1, or 0.7 are all valid values. A larger smoothing value implies stronger relationships between adjacent random variables in the graph.
- JSON
- Data in the JavaScript Object Notation format. An open standard format that uses human-readable text to transmit data objects consisting of attribute/value pairs. For more information see `http:/json.org`__.
- K-S Test
From Wikipedia: Kolmogorov|EM|Smirnov Test:
In statistics, the K-S test is a nonparametric test of the equality of continuous, one-dimensional probability distributions that can be used to compare a sample with a reference probability distribution (one-sample K-S test), or to compare two samples (two-sample K-S test). The K-S statistic quantifies a distance between the empirical distribution function of the sample and the cumulative distribution function of the reference distribution, or between the empirical distribution functions of two samples.- Katz Centrality
From Wikipedia: Katz Centrality:
In Social Network Analysis (SNA) there are various measures of centrality which determine the relative importance of an actor (or node) within the network. Katz centrality was introduced by Leo Katz in 1953 and is used to measure the degree of influence of an actor in a social network. [6] Unlike typical centrality measures which consider only the shortest path (the geodesic) between a pair of actors, Katz centrality measures influence by taking into account the total number of walks between a pair of actors. [7]- Label Propagation
A multi-pass process for grouping vertices.
See Label Propagation (LP).
For additional reference: Learning from Labeled and Unlabeled Data with Label Propagation.
- Labeled Data vs Unlabeled Data
From Wikipedia: Machine Learning / Algorithm Types:
Supervised learning algorithms are trained on labeled examples, in other words, input where the desired output is known. While Unsupervised learning algorithms operate on unlabeled examples, in other words, input where the desired output is unknown.Many machine-learning researchers have found that unlabeled data, when used in conjunction with a small amount of labeled data, can produce considerable improvement in learning accuracy.
For more information see: Wikipedia: Semi-Supervised Learning.
- Lambda
Adapted from: Stanford: Machine Learning:
This is the trade-off parameter, used in Label Propagation on Gaussian Random Fields. The regularization parameter is a control on fitting parameters. It is used in machine learning algorithms to prevent over-fitting. As the magnitude of the fitting parameter increases, there will be an increasing penalty on the cost function. This penalty is dependent on the squares of the parameters as well as the magnitude of lambda.- Lambda Function
An anonymous function or function literal in code. Lambda functions are used when a method requires a function as an input parameter and the function is coded directly in the method call.
Further examples and explanations can be found at this page: Python User Functions.
Related term: Python User-defined Function.
Warning
This term is often used where a Python user-defined function is more accurate. A key distinction is that the lambda function is not referable by a name.
- Latent Dirichlet Allocation
From Wikipedia: Latent Dirichlet Allocation:
[A] generative model that allows sets of observations to be explained by unobserved groups that explain why some parts of the data are similar. For example, if observations are words collected into documents, it posits that each document is a mixture of a small number of topics and that each word’s creation is attributable to one of the document’s topics. LDA is an example of a topic model and was first presented as a graphical model for topic discovery by David Blei, Andrew Ng, and Michael Jordan in 2003.- Least Squares
- A mathematical procedure for finding the best-fitting curve to a given set of points by minimizing the sum of the squares of the offsets (“the residuals”) of the points from the curve. The sum of the squares of the offsets is used instead of the offset absolute values because this allows the residuals to be treated as a continuous differentiable quantity. However, because squares of the offsets are used, outlying points can have a disproportionate effect on the fit, a property which may or may not be desirable depending on the problem at hand.
- LineFile
- A data format where the records are line-delimited.
- Local Clustering Coefficient
The local clustering coefficient of a vertex in a graph quantifies how close its neighbors are to being a clique (complete graph).
For more information see: Wikipedia: Local Clustering Coefficient.
See also Global Clustering Coefficient.
- Loopy Belief Propagation
Belief Propagation is an algorithm that makes inferences on graph models, like a Bayesian inference or Markov Random Fields. It is called Loopy when the algorithm runs iteratively until convergence.
For more information see: Wikipedia: Belief Propagation.
- Machine Learning
- Machine learning is a branch of artificial intelligence. It is about constructing and studying software that can “learn” from data. The more iterations the software computes, the better it gets at making that calculation. For more information, see Wikipedia.
- MapReduce
MapReduce is a programming model for processing large data sets with a parallel, distributed algorithm on a cluster. It is composed of a map() procedure that performs filtering and sorting (such as sorting students by first name into queues, one queue for each name) and a reduce() procedure that performs a summary operation (such as counting the number of students in each queue, yielding name frequencies). The “MapReduce System” (also called “infrastructure” or “framework”) orchestrates by marshaling the distributed servers, running the various tasks in parallel, managing all communications and data transfers between the various parts of the system, and providing for redundancy and fault tolerance.
For more information see: Wikipedia: MapReduce.
- Markov Random Fields
Markov Random fields, or Markov Network, are an undirected graph model that may be cyclic. This contrasts with Bayesian inference, which is directed and acyclic.
For more information see: Wikipedia: Markov Random Field.
- OLAP
Online analytical processing. An approach to answering MDA queries swiftly. The term OLAP was created as a slight modification of the traditional database term OLAP.
For more information see: Wikipedia: Online analytical processing.
- OLTP
Online transaction processing. A class of information systems that facilitate and manage transaction-oriented applications. OLAP involves gathering input information, processing the information and updating existing information to reflect the gathered and processed information.
For more information see: Wikipedia: Online transaction processing.
- PageRank
An algorithm to measure the importance of vertices.
PageRank works by counting the number and quality of edges to a vertex to determine a rough estimate of how important the vertex is. The underlying assumption is that more important vertices are likely to have more edges from other vertices.
For more information see: Wikipedia: PageRank.
- PageRank Centrality
- See Centrality.
- Precision/Recall
From Wikipedia: Precision and Recall:
In pattern recognition and information retrieval with binary classification, precision (also called positive predictive value) is the fraction of retrieved instances that are relevant, while recall (also known as sensitivity) is the fraction of relevant instances that are retrieved. Both precision and recall are therefore based on an understanding and measure of relevance.- Property Map
A property map is a key-value map. Both edges and vertices have property maps.
For more information see: Tinkerpop: Property Graph Model.
- Python User-defined Function
A Python User-defined Function (UDF) is a Python function written by the user on the client-side which can execute in a distributed fashion on the cluster. For further explanation, see Python User Functions
Further examples and explanations can be found at Python User Functions.
Related: Lambda Function.
- Quantile
- One value of a set that partitions a collection of data. Each partition (also known as a quantile) contains all the collection elements from the given value, up to (but not including) the lowest value of the next quantile.
- RDF
- See Resource Description Framework
- Receiver Operating Characteristic
From Wikipedia: Receiver Operating Characteristic:
In signal detection theory, a receiver operating characteristic (ROC), or simply ROC curve, is a graphical plot which illustrates the performance of a binary classifier system as its discrimination threshold is varied. It is created by plotting the fraction of true positives out of the total actual positives (TPR = true positive rate) vs. the fraction of false positives out of the total actual negatives (FPR = false positive rate), at various threshold settings. TPR is also known as sensitivity or recall in machine learning. The FPR is also known as the fall-out and can be calculated as one minus the more well known specificity. The ROC curve is then the sensitivity as a function of fall-out. In general, if both of the probability distributions for detection and false alarm are known, the ROC curve can be generated by plotting the Cumulative Distribution Function (area under the probability distribution from -inf to +inf) of the detection probability in the y-axis versus the Cumulative Distribution Function of the false alarm probability in x-axis.- Recommendation Systems
From Wikipedia: Recommender System:
- Resource Description Framework
- A specific format for storing graphs. Vertices also referred to as resources, have property/value pairs describing the resource. A vertex is any object which can be pointed to by a URI. Properties are attributes of the vertex, and values are either specific values for the attribute, or the URI for another vertex. For example, information in a particular vertex, might include the property “Author”. The value for the Author property could be either a string giving the name of the author, or a link to another resource describing the author. Sets of properties are defined within RDF Vocabularies (or schemas). A vertex may include properties defined in different schemas. The properties within a resource description are associated with a certain schema definition using the XML namespace mechanism.
- ROC
- See Receiver Operating Characteristic
- Row Functions
- Refer to Lambda Function and Python User-defined Function
- Schema
- A computer structure that defines the structure of something else.
- Semi-Supervised Learning
In Semi-Supervised learning algorithms, most the input data are not labeled and a small amount are labeled. The expectation is that the software “learns” to calculate faster than in either supervised or unsupervised algorithms.
For more information see: Supervised Learning, and Unsupervised Learning.
- Simple Random Sampling
In statistics, a simple random sample (SRS) is a subset of individuals (a sample) chosen from a larger set (a population). Each individual is chosen randomly and entirely by chance, such that each individual has the same probability of being chosen at any stage during the sampling process, and each subset of k individuals has the same probability of being chosen for the sample as any other subset of k individuals [1]. This process and technique is known as simple random sampling. A simple random sample is an unbiased surveying technique.
For more information see: Wikipedia: Simple Random Sample.
- Smoothing
Smoothing means to reduce the “noise” in a data set. “In smoothing, the data points of a signal are modified so individual points (presumably because of noise) are reduced, and points that are lower than the adjacent points are increased leading to a smoother signal.”
For more information see:
- Stratified Sampling
In statistics, stratified sampling is a method of sampling from a population. In statistical surveys, when subpopulations within an overall population vary, it is advantageous to sample each subpopulation (stratum) independently. Stratification is the process of dividing members of the population into homogeneous subgroups before sampling. The strata should be mutually exclusive: every element in the population must be assigned to only one stratum. The strata should also be collectively exhaustive: no population element can be excluded. Then simple random sampling or systematic sampling is applied within each stratum. This often improves the representativeness of the sample by reducing sampling error. It can produce a weighted mean that has less variability than the arithmetic mean of a simple random sample of the population.
For more information see: Wikipedia: Stratified Sampling.
- Superstep
Supersteps - A single iteration of an algorithm.
- Supervised Learning
Supervised learning refers to algorithms where the input data are all labeled, and the outcome of the calculation is known. These algorithms train the software to make a certain calculation.
For more information see: Unsupervised Learning, and Semi-Supervised Learning.
- Tab-Separated Variables
- See Character-Separated Values.
- Topic Modeling
- Topic models provide a simple way to analyze large volumes of unlabeled text. A “topic” consists of a cluster of words that frequently occur together. Using contextual clues, topic models can connect words with similar meanings and distinguish between uses of words with multiple meanings.
- Transaction Processing
From Wikipedia: Transaction Processing:
In computer science, transaction processing is information processing that is divided into individual, indivisible operations, called transactions. Each transaction must succeed or fail as a complete unit; it cannot be only partially complete.- Transactional Functionality
- See Transaction Processing.
- UDF
- See Python User-defined Function.
- Undirected Graph
An undirected graph is one in which the edges have no orientation (direction). The edge (a, b) is identical to the edge (b, a), in other words, they are not ordered pairs, but sets {u, v} (or 2-multisets) of vertices. The maximum number of edges in an undirected graph without a self-loop is

Contrast with Directed Acyclic Graph (DAG).
For more information see: Wikipedia: Undirected Graph.
- Unicode
- A data type consisting of a string of characters designed to represent all characters in the world, a universal character set.
- Unsupervised Learning
Unsupervised learning refers to algorithms where the input data are not labeled, and the outcome of the calculation is unknown. In this case, the software needs to “learn” how to make the calculation.
For more information see: Supervised Learning, and Semi-Supervised Learning.
- Vertex
A vertex is an object in a graph. Each vertex has an ID and a property map. The property map may contain 0 or more properties. Each vertex is connected to others by edges.
For more information see: Edge, and Tinkerpop: Property Graph Model.
- Vertex Degree
From Wikipedia: Vertex Degree:
In graph theory, the degree (or valency) of a vertex of a graph is the number of edges incident to the vertex, with loops counted twice [5]. The degree of a vertex is denoted  .
The maximum degree of a graph
.
The maximum degree of a graph  , denoted by
, denoted by
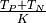 ,
and the minimum degree of a graph, denoted by
,
and the minimum degree of a graph, denoted by 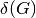 , are
the maximum and minimum degree of its vertices.
, are
the maximum and minimum degree of its vertices.- Vertex Degree Distribution
From Wikipedia: Degree Distribution:
In the study of graphs and networks, the degree of a node in a network is the number of connections it has to other nodes and the degree distribution is the probability distribution of these degrees over the whole network.- Vertices
- Plural form of Vertex.
Footnotes
| [1] | Yates, Daniel S.; David S. Moore, Daren S. Starnes (2008). The Practice of Statistics, 3rd Ed. Freeman. ISBN 978-0-7167-7309-2. |
| [2] | Francesco Ricci and Lior Rokach and Bracha Shapira (2011). Recommender Systems Handbook, pp. 1-35. Springer. |
| [3] | Lev Grossman (2010). How Computers Know What We Want |EM| Before We Do. Time. |
| [4] | Terveen, Loren; Hill, Will (2001). Beyond Recommender Systems: Helping People Help Each Other pp. 6. Addison-Wesley. |
| [5] | Diestel, Reinhard (2005). Graph Theory (3rd ed.). Berlin, New York: Springer-Verlag. ISBN 978-3-540-26183-4. |
| [6] | Katz, L. (1953). A New Status Index Derived from Sociometric Index. Psychometrika, 39-43. |
| [7] | Hanneman, R. A., & Riddle, M. (2005). Introduction to Social Network Methods. |
| [8] | Newman, M.E.J. 2010. Networks: An Introduction. Oxford, UK: Oxford University Press. |
| [9] | Weiss, Yair; Freeman, William T. (October 2001). “Correctness of Belief Propagation in Gaussian Graphical Models of Arbitrary Topology”. Neural Computation 13 (10): 2173|EM|2200. doi:10.1162/089976601750541769. PMID 11570995. |