Introduction¶
SimpactPurple is a parallelized (hence purple) agent-based model for simulating dynamic sexual networks and sexually transmitted diseases, specifically HIV. It is written in Python and is an ongoing project in the Simpact Simulation Suite. Here we cover download, installation, and overview of the simulation algorithm.
Download and Install¶
To download, grab the package from our github repository: https://github.com/seanluciotolentino/SimpactPurple/. After unpacking, navigate to the unpacked folder and run:
python setup.py install
from the command line. If you don’t have permissions to install software on the computer you’re using, you can install it to your user folder:
python setup.py install --user
Overview¶
Agent-based simulations of disease require defining how two main operations occur:
- Interactions: How are relationships (sexual or otherwise) formed and dissolved
- Infection: How is the disease (HIV in our case) transmitted
Also important, though sometimes omitted, is defining the progression of time. In influenza models this is not as important as the time scale tends to be short (six months to one year). This is more important for HIV models in which the simulation runs for 30 or more years.
These three operations are performed by the relationship operator, infection operator, and time operator in the Operators module. Each time step, the step method of each operator is called and performs a specific action. The infection operator simply goes through the edges of the sexual network (the relationship graph) and performs infections between serodiscordant pairs. The time operator goes through the list of agents and updates the grid queue of agents that have gotten too old for their current grid queue. Agents that are too old for the oldest grid queue are removed from the network and replaced with a new agent.
The Algorithm¶
From experience we know that producing a contact network resembling real life is the bottleneck in sexual network simulations. There are several reasons for this: The first being that we ideally want every individual to be potentially connected to every other individual even when there is an extremely small chance of forming a relationship. This means that there may be a large number of unlikely relationships which can cost have high cost in terms of memory consumption (SimpactWhite) or computation (SimpactBlu). The second reason is that we want to consider the preferences of both individuals who are forming the relationship. For example, the EMOD simulator [1] uses a queuing-based algorithm and runs efficiently, but the propensity of the relationship is only informed by the preference of males. The third reason is that we want the hazard of forming a relationship to depend on multiple dimensions of individuals characteristics. The Complex-Agent-Network (CAN) model presented by Sloot et. al forms relationships based only on a predefined desired number of partners [2], and does not lend itself to flexibility of other characteristics. Below we present our algorithm for relationship formation which solves these problems through parallelism and queues.
In order create a model which meets the three requirement outlined above and be able to handle sufficiently large populations, we need to take advantage of several aspects of the problem domain. In particular, we use the fact that similar individuals will yield similar hazard of formation for the same individual. For example, all else being equal, an 18-year-old female and an 19-year-old female have a similar chance of forming a relationship with an arbitrary 25-year-old male. We can take advantage of this by partitioning the population based on attributes that are significant in the hazard function.
We create a grid of queues with dimensions based on the attributes which we want to use to inform relationship formation. The initial proof-of-concept model creates a 2x10 grid of queues based on 2 sexes and 10 age categories (ages 15 to 65, grouped by 5). Therefore, we have a grid of queues, with each Grid Queue holding agents of a specific sex and age. With this grid of queues, we recruit agents to populate another queue, called the Main Queue (Figure 1). Recruited agents are placed into the Main Queue such that they are ordered near agents of the same Grid Queue. To form a relationship we take the top agent from the Main Queue, referred to as the suitor, and send a message to each Grid Queue that the suitor is looking for a match (Figure 2).
With the information about the suitor, each Grid Queue sorts its agents into a heap (in parallel) relative to each agent’s hazard relative to the suitor (Figure 3). Important formation metrics like age difference and mean age, which are approximately similar for every agent in the Grid Queue, are calculated just once for all of the agents. The Grid Queue then responds with a possible match from its Grid Queue (Figure 4), or None, meaning that none of the agents in the grid queue were willing to form a relationship with the suitor. From the returned possible matches, the suitor chooses a new partner, and the Grid Queues are updated if agents need to be removed.
We iterate through the Main Queue, making relationships for each agent. However, since we placed agents in the Main Queue based on their Grid Queue, it is possible that the next suitor is similar in terms of age and sex to the previous suitor. This means that the Grid Queues do not need to resort, since the hazard relative to the agent of this particular age and sex has already been calculated, and Grid Queues can return matches in constant time.
Figures¶
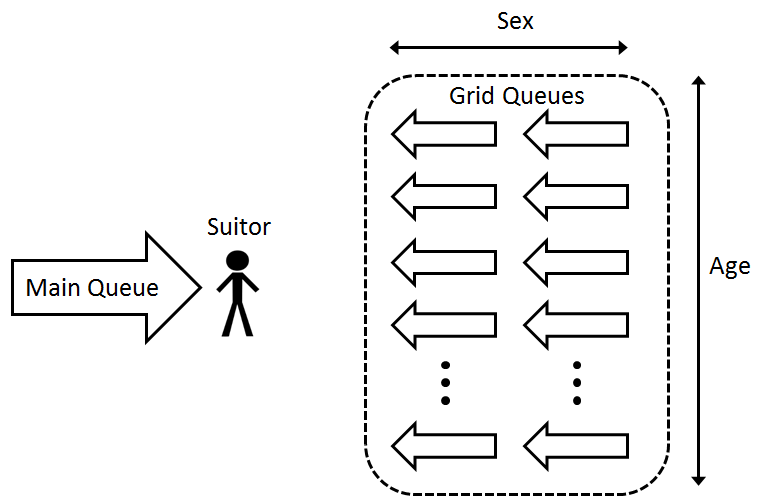
Figure 1: The simulation is made up of a grid of queues which holds all the agents, and a main queue which holds agents waiting to be matched. We refer to the agent at the head of the main queue as the suitor.
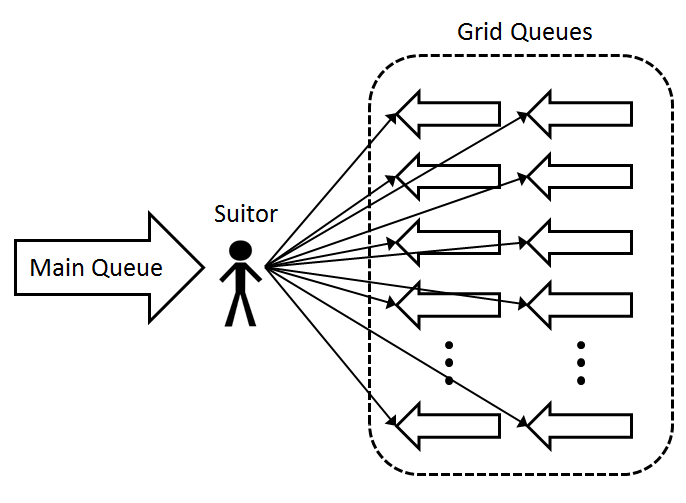
Figure 2: A message is sent to each Grid Queue, asking for a match to this particular suitor.
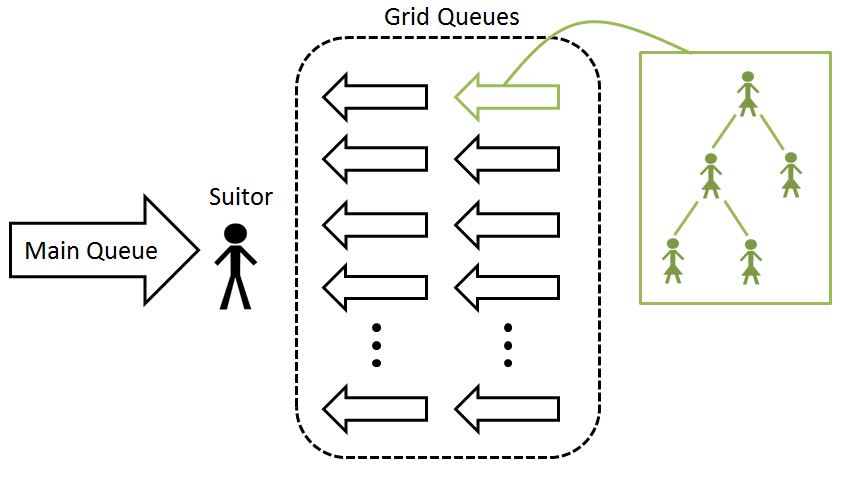
Figure 3: Each Grid Queue considers the request from a suitor in parallel by sorting their queue relative to the hazard of forming a relationship with the suitor. Note that the suitors Grid Queue ignores the suitor when returning possible matches.
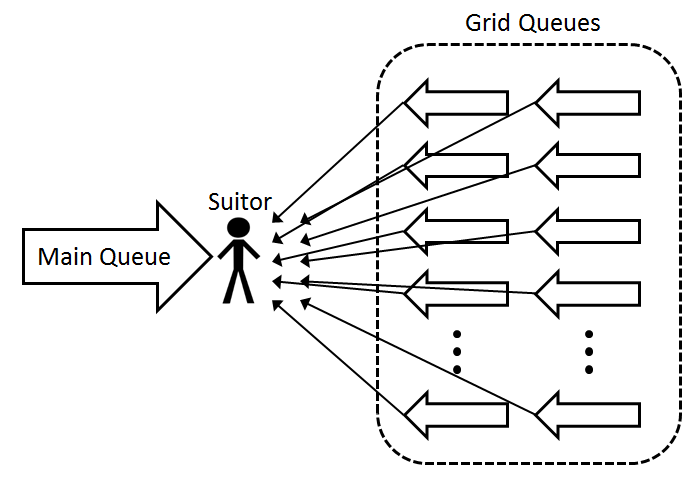
Figure 4: Queues return a possible match for the suitor. The suitor chooses a new partner from these matches.
Results¶
The queue-based method solves issues that were previously mentioned: Every individual has the possibility (even if minute) of forming a relationship with every other individual in the simulation. Our Grid Queues is a highbred approach which allows us to save relevant information for future matches and aggregate redundant calculations to reduce out workload. Additionally the algorithm considers the preferences of both individuals who are forming the relationship and can be made to consider multiple dimensions of individual’s characteristics easily.
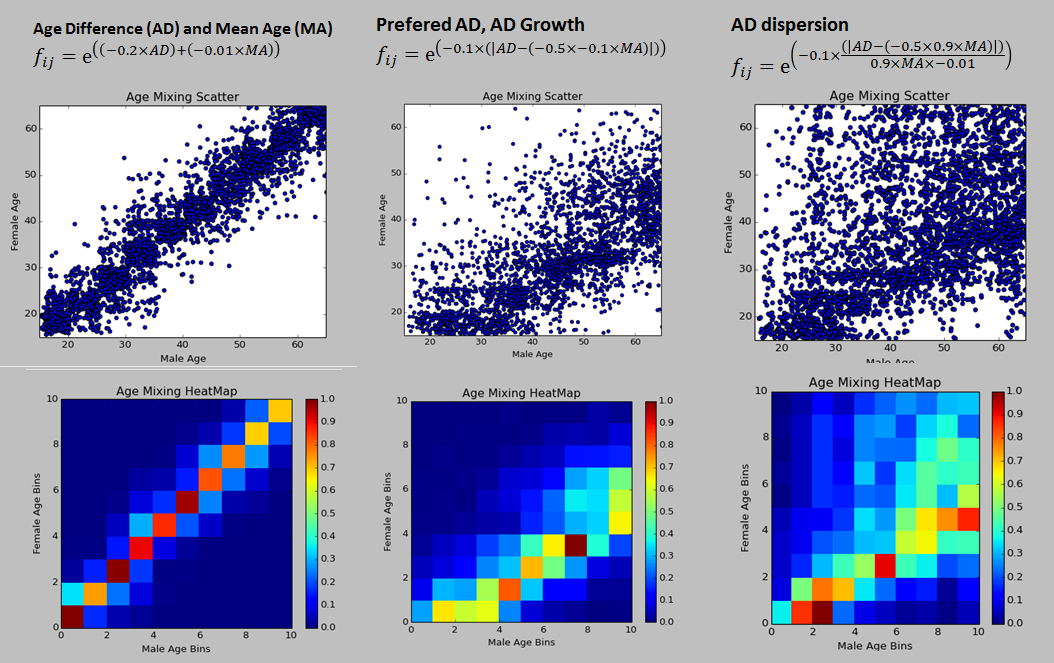
Figure 5 shows the age-mixing plots for different complex hazard functions that can be implemented. The simulations were run for 500 agents over three years for illustrative purposes. These examples show the flexibility of the model to consider different aspect when forming relationships.
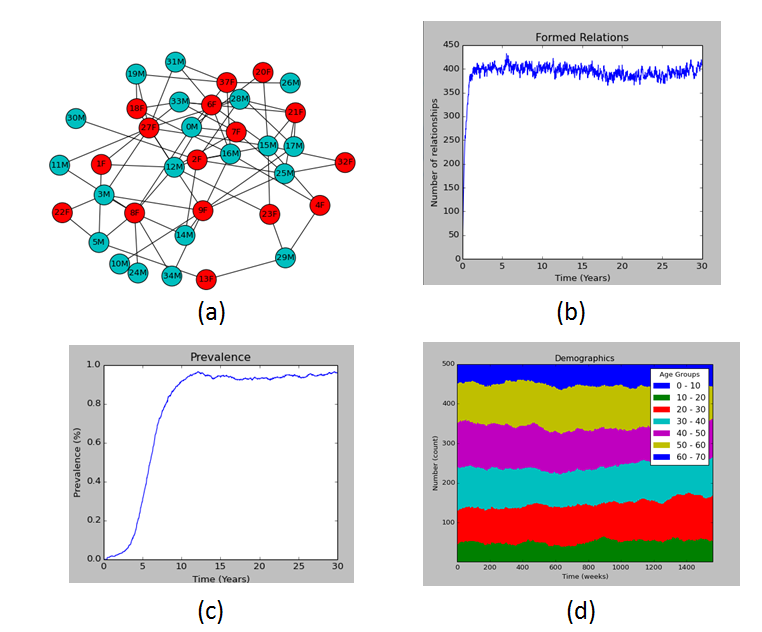
Figure 6 shows that the simulation is able to produce standard output one would expect from a disease simulator. Figure 7 shows the runtimes for a 30 year simulation for different population sizes. Simulations were run on a 16-core, 3.2 MHz computer. Note that while the algorithm has quadratic runtime, the quadratic coefficient is sufficiently small that larger populations’ sizes can be run.
| [1] | Bershteyn, Anna, Daniel J. Klein, and Philip A. Eckhoff. “Age-dependent partnering and the HIV transmission chain: a microsimulation analysis.” Journal of The Royal Society Interface 10.88 (2013). |
| [2] | Sloot, Peter MA, et al. “Stochastic simulation of HIV population dynamics through complex network modelling.” International Journal of Computer Mathematics 85.8 (2008): 1175-1187. |