September 06, 2010
shabti_rdfalchemy – an Object-RDF Mapper¶
Warning
Documentation in progress
About RDFAlchemy¶
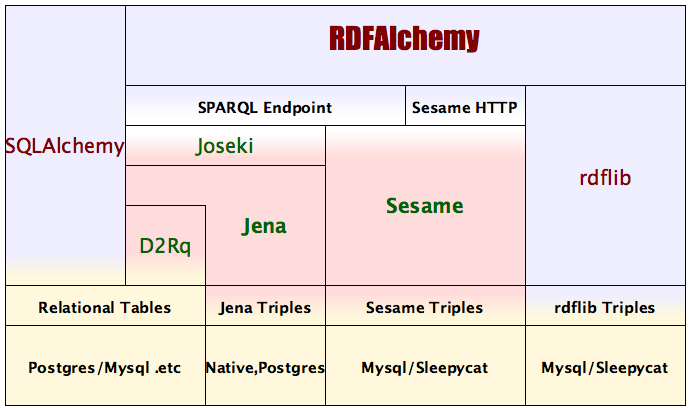
The goal of RDFAlchemy is to provide Python users with an object-type API access to an RDF triple store. In the same way that SQLAlchemy is an ORM (Object Relational Mapper) for relational database users, RDFAlchemy is an ORM (Object RDF Mapper) for RDF triple store users.
RDFAlchemy supports several different methods of connecting to triple stores (either as the exclusive persistence mechanism or in parallel with SQLAlchemy connections to conventional relational tables).
RDFAlchemy supports D2Rq access to relational tables, SPARQL access via Joseki to triples store maintained by either Jena or Sesame, REST access to Sesame-maintained triple stores and direct library access to rdflib-maintained triple stores (optionally either rdflib-specific or via the rdflib-Redland bridge).
The use of persistent objects in RDFAlchemy will be as close as possible to what it would be in SQLAlchemy. The aim is be able to write code such as:
>>> c = Company.get_by(symbol = 'IBM')
>>> print c.companyName
International Business Machines Corp.technical notes
Note
shabti_rdfalchemy source code is in the bitbucket code repository
Dependencies¶
As the below overview diagram suggests, the shabti auth rdfalchemy template requires certain dependencies to be satisfied. In a similar way that SQLAlchemy relies on psycopg2 to be able to connect to PostgreSQL, RDFAlchemy relies on the rdflib RDF library to be able to connect to triple stores.
Satisfying the rdflib dependency can present problems. The recommended approach is to follow the rdflib web site’s explicit easy_install instructions:
$ easy_install -U "rdflib>=2.4,<=3.0a"
Note
rdflib is somewhat “bleeding-edge” and not for the faint-hearted. A sphinx-generated version of the rdflib docs is available.
The bottom line of the overview diagram shows that choice of back-end storage is constrained by support limitations. When using rdflib to maintain triple stores, SQLite is the minimal functional requirement for persistence, however performance is likely to become an early issue because the triple stores tend to expand alarmingly quickly and performance is critically dependent on fast indexing.
From a practical perspective, MySQL is well-supported, ZODB and Sleepycat have proved to be unexpectedly quick (perhaps unhindered by RDBMS management processing), PostgreSQL (untuned) is disappointingly slow. Neither Jena nor Sesame stores are directly accessible from Pylons but both offer RESTful access.
Some additional practical notes of using RDFAlchemy with Pylons are available.