
The utils module contains classes and funtions of general utility used in multiple places throughout astropysics. Some of these are astropyhysics-specific algorithms while others are more python tricks.
The utils module is composed of three submodules to make organization clearer. The submodules are fairly different from each other, but the main uniting theme is that all of these submodules are not specific to a particularly astronomical application. Hence, they are available for re-use in astropysics or anywhere else they are deemed useful. The detailed documentation for each of the sub-modules is described below.
Note
The utils module is composed of submodules that can be accessed seperately. However, they are all also included in the base module. Thus, as an example, astropysics.utils.gen.DataObjectRegistry and astropysics.utils.DataObjectRegistry are different names for the same class (DataObjectRegistry). The astropysics.utils.DataObjectRegistry usage is preferred as this allows the internal organization to be changed if it is deemed necessary.
The gen module contains classes and functions of general utility used in various places throughout astropysics. These are python-specific utilities and hacks - general data-processing or numerical operations are in the alg module.
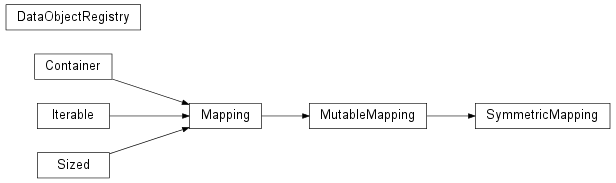
Bases: dict
A class to register data sets used throughout a module and enable easy access using string names.
Adds the registered object with the provided name to a group with the given name.
| Parameters: |
|---|
Generates and returns list of names of the objects in this registry, extracted from the name attribute of the object if present, otherwise from the registry key. The order is the same as that generated by keys() or values()
| Parameters: | retdicy – If True, the return value is a dictionary mapping keys from the registry to object names. |
|---|---|
| Returns: | List of names. |
Translates a string, sequence of strings, or mixed sequence of data objects and strings into a sequence of data objects.
| Parameters: |
|
|---|---|
| Type: | String, sequence of strings, or mixed sequence of strings and data objects. |
| Returns: | A sequence of data objects. |
Register a set of objects, possibly in a group
| Parameters: |
|
|---|
Bases: _abcoll.MutableMapping
A dict-like object that maps in two directions - the keys for one direction are the value for the other, and vice versa.
Note that this means all values most be unique and non-mutable.
Warning
This class is probably not at all thread safe.
initialized same as a dict
This class is a decorator indicating that the decorated object should have part (or all) of its docstring replaced by another object’s docstring.
The arguments are objects with a __name__ and __doc__ attribute. If a string of the form ‘{docstr:Name}’ is present in the decorated object’s docstring, it will be replaced by the docstring from the passed in object with __name__ of ‘Name’. Any arguments without a ‘{docstr:Whatever}’ to replace will be appended to the end of the decorated object’s docstring.
Examples
>>> def f1(x):
... '''Docstring 1'''
... pass
>>> def f2(x):
... '''
... Docstring 2
... and more!
... '''
... pass
>>> @add_docs(f1)
... def f3(x):
... '''
... Docstring 3
... '''
... pass
>>> @add_docs(f2)
... def f4(x):
... '''
... Docstring 3
... '''
... pass
>>> @add_docs(f1)
... def f5(x):
... '''
... Docstrong 2 {docstr:f1}
... '''
... pass
>>> f1.__doc__
'Docstring 1'
>>> f2.__doc__
'\n Docstring 2\n and more!\n '
>>> f3.__doc__
'\n Docstring 3\n \n Docstring 1'
>>> f4.__doc__
'\n Docstring 3\n \n Docstring 2\n and more!'
>>> f5.__doc__
'\n Docstrong 2 Docstring 1\n '
Does the same thing as replace_docs(), but also adds the function signature of the argument function to the replaced (followed by a newline). Note that this requires that the argument object be a function (and not anything with a __name__ and __doc__ attribute). This is typically useful for functions that do f(*args,**kwargs) to wrap some other function.
Sets the starting indentation of the provided docstring to the given indentation level.
| Parameters: |
|
|---|---|
| Returns: | a string like s with leading indentation removed. |
Call this function to check if the value matches the provided types.
| Parameters: |
|
|---|---|
| Raises: |
|
Note
If any of the types are a numpy.dtype, and the value is an numpy.array, the data type will also be checked.
The alg module contains basic algorithms, numerical tricks, and generic data processing tasks used in more than one place in astropysics.
Computes the angle of rotation and the rotation axis for a given rotation matrix.
| Parameters: |
|
|---|---|
| Returns: | an (angle,axis) tuple where the angle is in degrees if degrees is True, otherwise in radians |
Convinience function calling moments() to get the first normalized moment (i.e. the centroid).
| Parameters: |
|
|---|
See also
Generates a boolean mask for the point where the input crosses or has complted crossing (if between) from below (or above) a threshold.
If belowtoabove is True, the returned masks is for where the input transitions from below to above. Otherwise, from above to below.
| Parameters: |
|
|---|---|
| Returns: | A mask that is True where crossing occurs, False everywhere else. |
| Return type: | bool ndarray |
Examples
>>> from numpy import array,where
>>> xup = [-2,-1,0,1,2]
>>> xdn = [2,1,0,-1,-2]
>>> print crossmask(xup,0,True)
[False False True False False]
>>> print crossmask(xup,-0.5,True)
[False False True False False]
>>> print crossmask(xup,0.5,True)
[False False False True False]
>>> print crossmask(xdn,0,True)
[False False False False False]
>>> print crossmask(xdn,0,False)
[False False True False False]
>>> print crossmask(xdn,0.5,False)
[False False True False False]
>>> print crossmask(xdn,-0.5,False)
[False False False True False]
>>> xupdnup = [-2,-1,0,1,2,1,0,-1,-2,-1,0,1,2]
>>> where(crossmask(xupdnup,0.5,True))
(array([ 3, 11]),)
>>> print array(xupdnup)[crossmask(xupdnup,0,True)]
[0 0]
Estimates the background of the provided array following a technique specified by the method keyword:
outputs a scalar background estimate
Converts intrinsic ellipticity to observed where 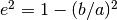
| Parameters: |
|
|---|---|
| Returns: | observed ellipticity |
Linearly rescales input values onto the range [base^lower,base^upper] and then applies the requested base of logarithm to the rescaled values.
| Parameters: |
|
|---|---|
| Returns: | logarithm of rescaled input |
Generates a grid of values given a sequence of 1D arrays. The inputs will be converted to 1-d vectors and the output is an array with dimensions (nvecs,n1,n2,n3,...) varying only on the dimension corresponding to its input order
Examples:
x = linspace(-1,1,10)
y = x**2+3
z = randn(13)
result = nd_grid(x,y,z)
xg,yg,zg = result
result will be a (3,10,10,13) array, and each of xg,yg, and zg are (10,10,13)
Search a sorted sequence for the nearest value.
| Parameters: |
|
|---|---|
| Returns: | nearest,inds Where nearest are the elements of a that are nearest to the val values, and inds are the indecies into a that give those values. |
See also
Converts observed ellipticity to intrinsic where
| Parameters: |
|
|---|---|
| Returns: | intrinsic ellipticity |
Generate a 3x3 rotation matrix in cartesian coordinates for rotation about the requested axis.
| Parameters: |
|
|---|---|
| Returns: | A numpy.matrix unitary rotation matrix. |
Computes the rotation matrix that moves the +z-axis (pole) to a new vector (x,y,z’) where x and y are specified and z’ is constrained by requiring the vector to be length-1.
| Parameters: | |
|---|---|
| Returns: | A numpy.matrix unitary rotation matrix. |
This performs the sigma clipping algorithm - i.e. the data will be iterated over, each time rejecting points that are more than a specified number of standard deviations discrepant.
| Parameters: |
|
|---|---|
| Returns: | A numpy.ma.Maskedarray with the rejected points masked, if maout is True. If maout is False, a tuple (filtereddata,mask) is returned where the mask is False for rejected points (and matches the shape of the input). |
The stats module contains classes and functions for statistics and statistical analysis. These tools in this module are mostly inspecific to astrophysics - the applications are all in the relevant other modules.
See also
scipy.stats - astropysics,utils.stats is intended only to provide utilites and interfaces that are not present in scipy.stats - when possible, scipy.stats should be used.
Bases: object
A class for Principal Component Analysis (PCA).
When mentioned in docstrings, p is the number of dimensions, and N is the number of data points.
| Parameters: |
|
|---|
input is an n X q array, where q <= p
output is p X n
Computes the covariance matrix for the dataset.
| Returns: | A p x p covariance matrix. |
|---|
Computes the eigenvalues and eigenvectors of the data set.
| Returns: | A 2-tuple (eigenvalues,eigenvectors) |
|---|
Computes and returns a length p array with the eigenvalues.
Computes and returns a p x p array with the eigenvalues.
Computes and returns a length p array with the eigenvalues normalized so that they sum to 1.
Generates a 2-dimensional plot of the data set and principle components using matplotlib.
ix specifies which p-dimension to put on the x-axis of the plot and iy specifies which to put on the y-axis (0-indexed)
Generates a 3-dimensional plot of the data set and principle components using mayavi.
ix, iy, and iz specify which of the input p-dimensions to place on each of the x,y,z axes, respectively (0-indexed).
projects the normalized values onto the components
enthresh, nPCs, and cumen determine how many PCs to use
if vals is None, the normalized data vectors are the values to project. Otherwise, it should be convertable to a p x N array
returns n,p(>threshold) dimension array
clips out all data points that are more than a certain number of standard deviations from the mean.
sigs can be either a single value or a length-p sequence that specifies the number of standard deviations along each of the p dimensions.
pc can be a scalar or any sequence of pc indecies
if vals is None, the source data is self.A, else whatever is in vals (which must be p x m)
Produces an array of weights that are generated by subdividing the values into n bins such that each bin has an equal share of the total number of values.
| Parameters: | |
|---|---|
| Returns: | An array of weights on [0,1] with shape matching values |
Computes the biweight midvariance of a sequence of data points, a robust statistic of scale.
For normal and uniform distributions, it is typically close to, but a bit above the variance.
| Parameters: |
|
|---|---|
| Returns: | biweight,median tuple (both floats) |
Computes the interquartile range for the provided sequence of values, a more robust estimator than the variance.
| Parameters: |
|
|---|---|
| Returns: | the interquartile range as a float |
Computes the median_absolute_deviation for the provided sequence of values, a more robust estimator than the variance.
| Parameters: |
|
|---|---|
| Returns: | the MAD as a float |
Compute the moments of the provided n-d array. That is
| Parameters: |
|
|---|---|
| Returns: | Either the computed moment if ms is a sequence, or a 1D array of moments for each dimension if ms is a scalar. |
The io module contains classes and functions for loading and saving data in various relevant formats used in astronomy, as well as convinience functions for retrieval of built-in data.
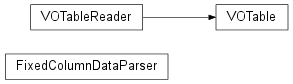
Bases: object
Parses a data file composed of lines with a fixed set of columns with the same number of bytes in each
| Parameters: |
|
|---|
| Parameters: |
|
|---|
Adds columns parsed from a file (typically a data file that will afterwards be read).
The parsed file is expected to have lines that begin with the columnlinestart argument and the rest of the line should be able to be split (using sep) into three or four columns in order name,lower,upper,format .
| Parameters: |
|
|---|---|
| Returns: | number of columns added |
Examples
For a file that starts like:
ID 0 3 int
data 4 10 float
moredata 11 15 int
use addColumnsFromFile(‘filename’,columnlinestart=None,sep=None,maxcols=3,firstcolindex=0)
And for a file with format specifier:
#... ID,1,4,int
#... data,5,11,float
#... moredata,12,16,int
use addColumnsFromFile(‘filename’,columnlinestart=’#... ‘,sep=’,’)
Parse a file that follows this object’s format.
| Parameters: | fn (string) – File name of the file to parse |
|---|---|
| Params maskedarray: | |
| If True, the function returns a masked array, otherwise a record array. | |
| Returns: | If maskedarray is False, a tuple (recarr,masks) where recarr is a numpy.core.records.recarray and masks is a dictionary mapping column names to masks. The masks are True if the value is valid, and False if not. If maskedarray is True, a numpy.ma.core.MaskedArray is returned. |
Writes a data array out to a data file using this format.
| Parameters: |
|
|---|---|
| Raises TypeError: | |
If the data dtype doesn’t match the columns. |
|
Bases: object
This class represents a VOTable. Currently, it is read-only, and will probably not be enhanced due to the existence of Michael Droettboom’s vo.table package (http://trac6.assembla.com/astrolib).
instantiate a VOTable object from an XML VOTable
If filename is True, the input string will be interpreted as a filename for a VOTable, otherwise s will be interpreted as an XML-formatted string with the VOTable data
Pickle an object to a specified file.
| Parameters: |
|
|---|
Unpickle a pickled object from a specified file and return the contents.
| Parameters: | |
|---|---|
| Returns: | A list of length given by number or a single object if number<1 |
Retrieves a data file from a remote source (usually the internet), and optionally caches that data locally. See set_data_store() for control of caching behavior, and set_data_download_reporter() for control of download progress reporting.
| Parameters: |
|
|---|---|
| Returns: | A file-like object or a string (see asfile) |
| Raises: |
|
Note
The data accessed by this function is distinct from the data accessed via get_package_data(). Package data is crucial basic data included in the astropysics source distribution, while standard data is for larger or optional data files that are downloaded as needed.
Returns the current behavior of the download progress reporter for get_data(). See set_data_download_reporter() for details of the possible values.
| Returns: | The current value of the data store. Possible values are listed in set_data_download_reporter(). |
|---|
Returns the current behavior of the caching mechanism for get_data(). See set_data_store() for details of the possible values
| Returns: | The current value of the data store. Possible values are listed in set_data_store(). |
|---|
Use this function to load data files distributed with the astropysics source code.
| Parameters: | dataname (str) – The name of a file in the package data directory. |
|---|---|
| Returns: | The content of the requested file as a string. |
Note
The data accessed by this function is distinct from the data accessed via get_data(). Package data is crucial basic data included in the astropysics source distribution, while standard data is for larger or optional data files that are downloaded as needed.
loads all deimos spectra found in the specified directory that match the requested pattern and returns a list of the file names and the Spectrum objects.
extraction and smoothing are the same as for load_deimos_spectrum
verbose indicates if information should be printed
returns dictionary mapping file names to Spectrum objects
extraction type can ‘horne’ or ‘boxcar’
if smoothing is positive, it is gaussian sigmas, if negative, boxcar pixels
returns Spectrum object with ivar, [bdata,rdata]
This function loads a file in the Tipsy ASCII format (http://www-hpcc.astro.washington.edu/tipsy/man/readascii.html) and outputs a dictionary with entries for grouped data
Loads a linear spectrum from a fits file with WCS keywords ‘CD1_1’ or ‘CDELT1’ and ‘CRVAL_1’.
| Parameters: |
|
|---|---|
| Returns: | An astropysics.spec.Spectrum object |
| Raises: |
|
Loads a fixed column data file using FixedColumnDataParser.
| Parameters: |
|
|---|
For other arguments see extra documentation below and FixedColumnDataParser.
Additional keywords are passed into numpy.loadtxt().
| Returns: | recarray or a regular ndarray with data loaded from the text file. |
|---|
To match the default format, data files to load should look like:
#:col1 1 4 int
#:col2 6 6 bool
#:col3 8 10 S3
#:col4 12 16 float {'------':''}
# could have a comment here if you want
1239 1 abc 12.325
2489 0 zyx ------
9526 1 qwe 89632.
FixedColumnDataParser.parseFile() describes the return types and maskedarray parameter.
For details on arguments controlling how columns are inferred, See FixedColumnDataParser.addColumnsFromFile().
Load a text file into a structured numpy array where the field names and types are inferred from a line (typically the first) in the file.
It must begin with a comment (specified by the ‘comments’ keyword) and have fields (sperated by the delimiter, default whitespace) composed of a colon-seperated field name and valid numpy dtype (e.g. ‘f’ for floats or ‘i’ for integers).
If a third colon-seperated component is present, it is a python expression (with no spaces) that can be used to derive the value for that column given values from the other columns. numpy functions can be used with the prefix ‘np’.
An example field line might be:
#data1:f derived:f:data1+data2**2 data2:i
This will result in a 3-field record array with fields ‘data1’, ‘derived’, and ‘data2’, where data1 and data2 are the columns of the input file.
| Parameters: |
|
|---|
extra keywords are passed into numpy.loadtxt()
| Returns: | A numpy record array or regular array with data from the text file. |
|---|
Note
The updatedict parameter is seful for injecting the loaded file into the local namespace: loadtxt_text_fields(...,updatedict=locals()).
This is a convinience function for pyfits, allowing the following usage in python 2.5 or above (in 2.5, from __future__ import with_statement is needed at the beginning of the file):
from astropysics.utils.io import open_with_pyfits
with open_with_pyfits('filename') as f:
h = f[0].header
d = f[0].data
# ... do something more with the file...
# at this indent level, the pyfits file is now closed. It will also be
# closed if an exception is thrown.
The arguments are the same as for pyfits.open().
Sets the behavior of the download progress reporter for get_data(). The value can subsequently be retrieved via get_data_download_reporter().
| Parameters: | reportprogress – If False, no progress reports go out while file is downloading. If True, a progress message is printed at the command line. Otherwise, this must be a callable. |
|---|
Note
If reportprogress is a callable, it will be called as func(progress,started,finished,url), where progress is either a float between 0 and 1 indicating the fraction of the file downloaded (if the file size is known), or the number of bytes downloaded if the file size is unknown (1 or larger). started is True if the download has begun, and finished is True when the download has finished. The function will always be called at the beginning as func(0,False,False) and once at the end as func(?,True,True). url is a string with the target URL.
| Raises TypeError: | |
|---|---|
| If reportprogress is an inappropriate type | |
Note
If set_data_store() has been set to False, no download progress will be reported, as the data will be retrieved immediately without download to a local file.
Sets the behavior of the caching mechanism when get_data() is called. The value can subsequently be retrieved via get_data_store().
| Parameters: | store – If True, when get_data() is called the data file will only be downloaded if that URL is accessed for the first time. If False, the data will always be retrieved from the remote source and not saved. If it is the string ‘refresh’, the file is downloaded regardless of whether or not it is present, but the downloaded version will be used in future calls where it is True. |
|---|---|
| Raises TypeError: | |
| If store is an inappropriate type | |
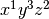 .
.