How the background models were tuned¶
In this section we explain in details how the each algorithm was tuned and give instructions on how to reproduce the results.
How the dabase is organized for the fine tuning?¶
Collected by University of Reading, the Cross-Spectrum Iris/Periocular contains VIS and NIR periocular images from the same subjects form the left and right eyes.
- The dataset contains a total of 20 subjects and for each subject it has:
- 8 VIS captures from the left eye
- 8 NIR captures from the left eye
- 8 VIS captures from the right eye
- 8 NIR captures from the right eye
Here we are considering that each eye is an independent observation. Hence, the database has 40 subjects.
In order to tune our verification system, we provide in this python package bob.db.pericrosseye 5 evaluation protocols called: cross-eye-VIS-NIR-split1, cross-eye-VIS-NIR-split2,
cross-eye-VIS-NIR-split3, cross-eye-VIS-NIR-split4 and cross-eye-VIS-NIR-split5.
For each protocol we split the 40 subjects in 3 subsets called `world`, `dev` and `eval`.
The `world` set is composed by 20 clients and it is designed to be used as the training set.
The `dev` set is composed by 10 clients and it is designed to tune the hyper-parameters of a hererogeneous face recognition approach and to be the decision threshold reference.
The `eval` set is composed by 10 clients and it is used to assess the final unbiased system performance.
Preprocessing¶
The images of the periocular region were simply gray scaled and cropped in 3 different image sizes:
- 25x25 pixels
- 50x50 pixels
- 75x75 pixels


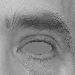
No geometric normalization strategy was applied, so far.
Algorithms¶
Here we will present three groups of algorithms. The first group are just simple strategies to approach the problem (LDA, PCA, etc...). The second group are strategies based on Geodesic Flow Kernel for domain adaptation. The third group are strategies based on Gaussian Mixture Models.
Each algorithm is evaluated using three diferent metrics (EER/HTER, FRR with FAR=1% and FRR with FAR=0.1%). For the EER/HTER, the decision threshold is computed using as a reference the Equal Error Rate (EER) on the dev set of the database. With this threshold, the Half Total Error Rate (HTER) is reported in the eval set. In the FRR with FAR=1% the decision threshold is defined in the dev set where the False Aceptance Rate (FAR) is equals to 1%. With this threshold, the False Rejection Rate (FRR) is reported in the eval set. The FRR with FAR=0.1% is the same as the one before, execept that the FAR is equals to 0.1%.
Simple Strategies¶
For the moment with put inplace three algorithms and their performance in terms of error rate are reported in the table bellow.
The PCA is the Principal Component Analisys [TP91] on the raw pixels of the dataset. About this one, there is nothing to be said, except that we kept 99% of the energy in the final projection.
The LDA is the Linear Discriminant Analisys on the raw picels of the dataset. For this one, we trained a PCA keeping 99% of the energy before the LDA training. The final matrix has 19 dimension (number of clients in the world set minus 1).
The training procedures of aforementioned strategies does not consider the modality are a prior.
The H-PCA is the PCA as before, but with a mean covariate shift from VIS to NIR images.
| Image size | Subspaces | Feat. | EER/HTER (%) | FRR with FAR=1% | FRR with FAR=0.1% | |||
|---|---|---|---|---|---|---|---|---|
| dev | eval | dev | eval | dev | eval | |||
| 75x75 | 0.99 | LDA | 16.22(6.49) | 14.06(5.31) | 40.5(4.3) | 40.25(13.29) | 52.5(3.62) | 58.5(11.41) |
| PCA | 16.28(4.21) | 18.18(2.71) | 49.5(9.57) | 56.5(14.74) | 68.5(14.99) | 73.0(14.95) | ||
| H-PCA | 16.22(4.17) | 18.54(3.01) | 53.75(10.98) | 64.25(11.42) | 68.75(15.81) | 78.75(10.0) | ||
Geodesic Flow Kernel¶
The Geodesic Flow Kernel (GFK) models the source domain and the target domain with d-dimensional linear subspaces and embeds them onto a Grassmann manifold.
Specifically, let denote the basis of the PCA subspaces for each of the two domains, respectively.
The Grassmann manifold 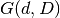 is the collection of all d-dimensional subspaces of the feature vector space
is the collection of all d-dimensional subspaces of the feature vector space 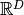 .
.
The geodesic flow 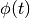 between
between 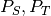 on the manifold parameterizes a path connecting the two subspaces.
In this work we considered
on the manifold parameterizes a path connecting the two subspaces.
In this work we considered 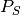 as the linear subspace of the VIS images and
as the linear subspace of the VIS images and 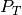 as the linear subspace of NIR images.
as the linear subspace of NIR images.
The original features are projected into these subspaces and forms a feature vector of infinite dimensions.
Using the new feature representation for learning, will force the classifiers to NOT lean towards either the source domain or the target domain, or in other words, will force the classifier to use domain-invariant features.
The infinite-dimensional feature vector is handled conveniently by their inner product that gives rise to a positive semidefinite kernel 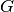 defined on the original features.
Details of the strategy can be found [Gong12]
defined on the original features.
Details of the strategy can be found [Gong12]
Three types of the features were tested so far for this approach. And they are described in the next two subsections.
Gabor features¶
The idea of the Graphs algorithm relies on a Gabor wavelet transform. The periocular image is transformed using a family of 40 complex-valued Gabor wavelets, which is divided into the common set of 8 orientations and 5 scales. The result of the Gabor transform are 40 complex-valued image planes in the resolution of the periocular image. Commonly, each complex-valued plane is represented by absolute values and phases.
From these complex planes, grid graphs of Gabor jets are extracted. A Gabor jet is a local texture feature, which is generated by concatenating the responses of all Gabor wavelets at a certain offset-position in the image. This offset is computed around the eye region. Four landmarks are detected in the eyes (eyes corners) and, from these landmarks, other landmarks are inferered as a result of an expansion in several angles and radii (in pixels). The result of the landmark detection can be seen in the image bellow:

At training time (offline), we used the `world` set to compute the Kernel using the absolute values of the planes of each Gabor jet.
For 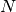 Gabor jets, we have
Gabor jets, we have 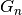 kernels (
kernels (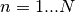 ).
).
At enrolling time, given a periocular image 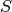 , the absolute values of the Gabor jets are computed and stored.
, the absolute values of the Gabor jets are computed and stored.
Finally, at scoring time, given the template and the gabor jets of a probe image 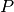 , the score value is defined as
, the score value is defined as 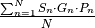 .
.
Follow bellow the results of this approach in terms of EER/HTER, FAR 1% and FAR 0.1%.
| Image size | radius | angle | EER/HTER (%) | FRR with FAR=1% | FRR with FAR=0.1% | |||
|---|---|---|---|---|---|---|---|---|
| dev | eval | dev | eval | dev | eval | |||
| 800x900 | [50 .. 150] | 20 | 1.0(0.94) | 1.74(1.32) | 1.75(2.32) | 2.5(3.06) | 2.75(2.89) | 2.5(3.06) |
| [50 .. 200] | 20 | 0.89(0.77) | 1.5(1.17) | 1.0(0.94) | 2.0(2.57) | 3.0(2.81) | 2.5(3.06) | |
| [50 .. 250] | 6 | 0.97(0.86) | 1.36(1.2) | 1.25(1.12) | 1.75(2.92) | 2.5(2.24) | 3.75(5.36) | |
| 7 | 0.67(0.57) | 0.96(0.82) | 0.5(0.61) | 1.25(1.94) | 1.75(1.5) | 2.25(3.39) | ||
| 20 | 0.53(0.59) | 1.07(0.96) | 0.75(1.0) | 1.0(1.46) | 1.75(2.45) | 1.5(2.0) | ||
| [50 .. 300] | 5 | 1.17(0.81) | 2.0(1.78) | 1.0(0.94) | 2.25(3.39) | 2.75(2.15) | 2.75(4.36) | |
| 20 | 0.78(0.58) | 1.78(1.61) | 0.75(0.61) | 2.0(3.41) | 2.25(3.3) | 2.5(4.4) | ||
We can hypothesize that the geometric position of the jets around the eyes is not important when the flow between the modalities is modeled in the Grassmann.
This can simplify the modeling proccess allowing us to have only one as background model.
This can be achieved by, at training time, stacking the absolute values of the planes of each Gabor jet.
The enrollment process is the same as before, and the scoring function can be computed as: 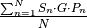 .
.
Follow bellow the results of this simplification in terms of EER/HTER, FAR 1% and FAR 0.1%.
| Image size | radius | angle | EER/HTER (%) | FRR with FAR=1% | FRR with FAR=0.1% | |||
|---|---|---|---|---|---|---|---|---|
| dev | eval | dev | eval | dev | eval | |||
| 800x900 | [50 .. 150] | 20 | 2.14(1.91) | 3.46(1.08) | 2.75(2.89) | 2.0(2.57) | 4.25(3.02) | 3.25(3.12) |
| [50 .. 200] | 20 | 2.58(2.55) | 2.62(1.63) | 2.75(2.89) | 1.75(2.45) | 3.25(2.57) | 2.25(3.0) | |
| [50 .. 250] | 6 | 1.75(1.87) | 2.5(1.62) | 3.0(2.92) | 1.5(2.0) | 3.25(3.12) | 2.0(2.92) | |
| 7 | 1.58(1.38) | 2.18(1.28) | 2.0(2.03) | 1.0(1.46) | 3.25(2.57) | 2.0(2.92) | ||
| 20 | 1.64(1.74) | 1.99(1.58) | 2.0(2.45) | 1.25(1.94) | 3.0(3.22) | 1.5(2.42) | ||
This simplification increases significatively the number of features per client and allow us to use supervised methods,
such as, LDA to build 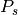 and
and 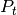 .
.
| Image size | radius | angle | EER/HTER (%) | FRR with FAR=1% | FRR with FAR=0.1% | |||
|---|---|---|---|---|---|---|---|---|
| dev | eval | dev | eval | dev | eval | |||
| 800x900 | [50 .. 250] | 20s | 2.08(2.64) | 2.06(1.38) | 2.5(3.06) | 1.25(2.5) | 2.5(3.06) | 1.5(3.0) |
| [50 .. 250] | 20 | 0.42(0.77) | 0.94(1.12) | 0.5(1.0) | 0.75(1.5) | 1.0(2.0) | 1.0(2.0) | |
| [50 75 250] | 20 | 0.28(0.56) | 0.89(1.14) | 1.25(2.5) | 0.25(0.5) | 1.25(2.5) | 0.75(1.5) | |
| [50 75 300] | 20 | 0.25(0.5) | 0.96(1.27) | 1.0(2.0) | 0.0(0.0) | 1.25(2.5) | 0.75(1.5) | |
Other features¶
In this set of experiments we used two types of features: no features (pixels only; pix in the table below) and Local Binary Patterns (LBP) [HRM06].
For both, the periocular images were resized to 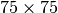 and no extra image preprocessing was applied.
For the LBP, the images were sampled in patches of
and no extra image preprocessing was applied.
For the LBP, the images were sampled in patches of 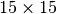 . Two experiments were executed in this configuration.
One with an overlap of 7 pixels (LBP-o in the table) and one with no overlap (LBP in the table).
. Two experiments were executed in this configuration.
One with an overlap of 7 pixels (LBP-o in the table) and one with no overlap (LBP in the table).
The error rate can be observed in the table below.
| Image size | Subspaces | Feat. | EER/HTER (%) | FRR with FAR=1% | FRR with FAR=0.1% | |||
|---|---|---|---|---|---|---|---|---|
| dev | eval | dev | eval | dev | eval | |||
| 75x75 | automatic | pix. | 19.03(3.56) | 18.43(1.53) | 88.5(14.86) | 86.0(26.77) | 94.5(10.39) | 88.25(23.5) |
| LBP | 15.86(3.21) | 13.08(1.93) | 68.0(12.29) | 56.75(14.24) | 82.0(11.72) | 70.25(19.24) | ||
| LBP-o | 16.89(5.08) | 14.67(2.77) | 69.75(10.97) | 61.25(19.64) | 84.25(6.87) | 68.25(18.43) | ||
Intersession Variability Modelling (ISV)¶
Built on top of Gaussian Mixture Models (GMM), Intersession Variability Modelling (ISV) proposes to explicitly model the variations between different modalities by learning a linear subspace in the GMM supervector space. These variations are compensated during the enrolment and testing time.
This strategy is similar to the one implemented in [FRE16]. Including the image size, two variables were fine tuned: the number of Gaussians and the dimension of the Session Varibility space (U). In the table bellow, the results are presented in terms of EER/HTER, FAR 1% and FAR 0.1%. In order to analise the generalization of the algorithm, the decision threshold for each metric was chosen using the development set as a reference.
| Image size | Gaussians | U | EER/HTER (%) | FRR with FAR=1% | FRR with FAR=0.1% | |||
|---|---|---|---|---|---|---|---|---|
| dev | eval | dev | eval | dev | eval | |||
| 50x50 | 16 | 100 | 5.28(2.99) | 5.13(1.49) | 13.0(9.17) | 15.75(8.9) | 25.0(22.11) | 28.25(16.65) |
| 32 | 100 | 2.44(2.69) | 4.5(2.34) | 9.5(13.75) | 11.5(9.98) | 19.0(22.32) | 21.25(21.05) | |
| 64 | 100 | 2.5(2.79) | 4.28(3.14) | 6.75(7.81) | 10.75(9.57) | 12.75(15.66) | 15.25(15.52) | |
| 128 | 100 | 1.86(2.39) | 2.26(2.16) | 3.5(5.78) | 2.25(3.3) | 6.75(11.03) | 6.0(5.99) | |
| 256 | 100 | 1.19(1.27) | 2.29(2.35) | 4.5(7.77) | 5.25(4.57) | 6.0(10.76) | 7.5(6.42) | |
| 512 | 100 | 1.44(1.73) | 1.92(1.94) | 2.25(3.3) | 3.75(4.11) | 4.0(6.77) | 4.0(3.91) | |
| 25x25 | 128 | 100 | 2.64(2.57) | 2.0(2.09) | 4.25(3.5) | 6.25(7.16) | 7.5(6.27) | 10.5(8.86) |
| 512 | 100 | 2.5(2.05) | 3.58(3.03) | 7.25(5.99) | 13.0(9.8) | 16.25(14.32) | 21.75(16.1) | |
| 75x75 | 128 | 100 | 2.06(2.42) | 1.68(1.74) | 2.5(3.26) | 3.75(4.11) | 2.5(3.26) | 4.0(4.43) |
| 512 | 50 | 0.75(0.61) | 1.15(1.64) | 0.75(0.61) | 0.0(0.0) | 0.75(0.61) | 1.25(0.79) | |
| 512 | 80 | 0.75(0.61) | 1.28(1.63) | 0.75(0.61) | 0.0(0.0) | 0.75(0.61) | 2.25(2.67) | |
| 512 | 100 | 0.75(0.61) | 2.58(1.46) | 0.75(0.61) | 0.0(0.0) | 0.75(0.61) | 3.75(3.06) | |
| 512 | 120 | 0.75(0.61) | 2.5(1.53) | 0.75(0.61) | 0.0(0.0) | 0.75(0.61) | 3.25(2.45) | |
| 512 | 160 | 0.75(0.61) | 2.5(1.43) | 0.75(0.61) | 0.0(0.0) | 0.75(0.61) | 2.75(1.84) | |
| 90x90 | 512 | 100 | 0.75(0.61) | 0.87(1.46) | 0.75(0.61) | 0.25(0.5) | 0.75(0.61) | 1.25(0.79) |
| 512 | 160 | 0.75(0.61) | 1.0(1.7) | 0.75(0.61) | 0.25(0.5) | 0.75(0.61) | 0.75(1.0) | |
References¶
| [FRE16] | de Freitas Pereira, Tiago, and Sébastien Marcel. “Heterogeneous Face Recognition using Inter-Session Variability Modelling.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops. 2016. |
| [TP91] | M. Turk and A. Pentland. Eigenfaces for recognition. Journal of Cognitive Neuroscience, 3(1):71-86, 1991 |
| [HRM06] | G. Heusch, Y. Rodriguez, and S. Marcel. Local Binary Patterns as an Image Preprocessing for Face Authentication. In IEEE International Conference on Automatic Face and Gesture Recognition (AFGR), 2006. |
| [Gong12] | Gong, Boqing, et al. “Geodesic flow kernel for unsupervised domain adaptation.” Computer Vision and Pattern Recognition (CVPR), 2012 IEEE Conference on. IEEE, 2012. |